


Measuring how LLMs recommend brands & sites — with open data, code, and a reproducible method
Summary: We ran 15,600 samples across 52 categories/locales to study how LLMs (ChatGPT, Claude, Gemini, etc.) mention or rank brands/sites. We open-sourced the method (Entity-Conditioned Probing + Resampling), data, and code so teams can audit, reproduce, and extend.
Links:
- Preprint (Zenodo): https://zenodo.org/records/17489350
- Code (GitHub): https://github.com/jim-seovendor/entity-probe
- Data (Hugging Face): https://huggingface.co/datasets/seovendorco/entity-probe
- Contact: ask@seovendor.co
This study is a follow-up research project from our first In-Depth Study: ChatGPT’s Impact on Business Visibility and Branding by 100X Multi-Sampling.
Why this matters
LLMs increasingly act like recommenders. For queries like “best [tool]” or “top [service]”, users often see a small set of brands/sites. If you’re building AI products or care about brand visibility, you need answers to:
- Which brands/sites appear most often?
- How stable are those results across samples, locales, and models?
- How reliable is a “top-k” list derived from an LLM?
Our goal: provide a transparent, reproducible way to measure and discuss LLM “recommendations.” – Jim Liu, CEO, SEO Vendor
What is RankLens Entities?
A public, reproducible suite for measuring LLM brand/site visibility:
- Method: Entity-Conditioned Probing (ECP) with multi-sampling + half-split consensus to estimate reliability (overlap@k).
- Data: 15,600 samples over 52 categories/locales, with parsed entities and metadata.
- Code: Scripts to aggregate lists, compute consensus top-k, and evaluate reliability.

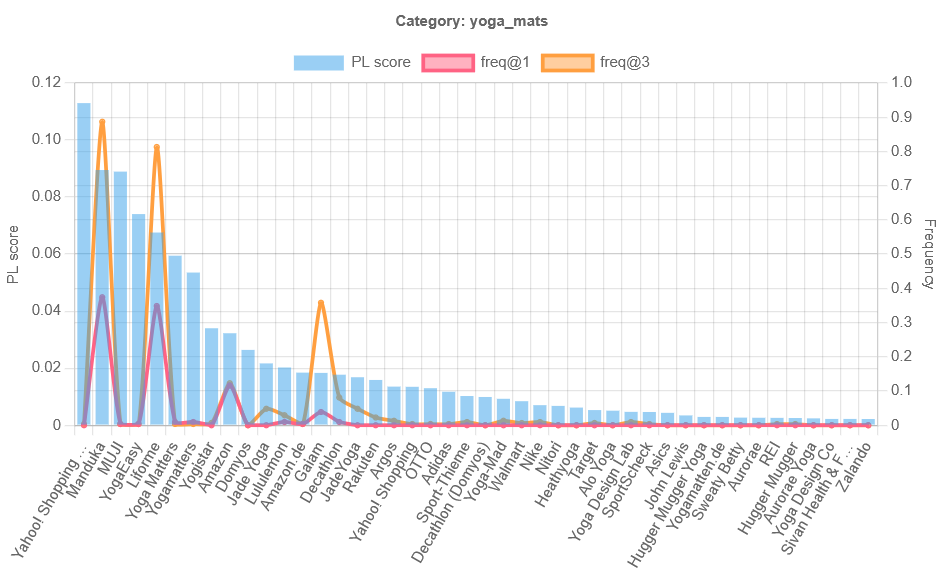
Key findings (high level)
- Reliability varies by category & locale. Some categories show high overlap@k; others are volatile.
- Alias risk is real. The same brand can appear under multiple strings (e.g., “Acme CRM”, “acme.com”). Normalization helps but isn’t perfect.
- Prompt sensitivity exists. Small phrasing changes can shift inclusion/ordering—use multi-sampling and track prompts.
- Model drift happens. Time-stamp runs and avoid comparing apples to oranges across model updates.
Who it’s for
- AI/ML engineers: a reproducible eval harness for LLM list-style answers.
- SEO/marketing teams: visibility tracking for brands/sites in LLM responses.
- Researchers: open artifacts + method to extend, critique, or benchmark.
What’s included
- Preprint: full method + limitations and guidance.
- Repository: parsing, consensus, reliability metrics, export utilities.
- Dataset: per-prompt lists, JSONL results, schema docs.
- Examples: ready-to-run code for overlap@k and consensus top-k.
How it works (quick overview)
- Probe each (category, locale, model) with standardized prompts.
- Parse responses into entity lists (brands/sites).
- Resample & split: divide lists into two halves.
- Consensus: compute top-k for each half via frequency aggregation.
- Reliability: measure overlap@k between the halves.
If overlap@k is high → the “top-k” is likely stable for that setup. Low → treat any single top-k as noisy.
Limitations (read before using)
- Not a ranking of “truth,” but a measurement of what LLMs surface under given conditions.
- Aliases & normalization: we include baseline rules; entity resolution is imperfect.
- Prompt & temperature sensitivity: track your configurations; use multi-sampling.
- Locale effects: some markets/categories are intrinsically turbulent.
- Model updates: repeat runs over time to monitor drift.
Get started
- Skim the preprint for method + caveats.
- Clone the repo and run the overlap@k example.
- Load the dataset (CSV/JSONL) and reproduce a chart.
- Add your category/locale and compare reliability.
- Open a PR with improvements (normalizers, metrics, charts).
FAQ
Is this a product?
No—the study and artifacts are open for research and transparency; they inform products but aren’t a product themselves.
Can I cite this?
Yes. Cite the Zenodo preprint; include the GitHub repo and dataset link.
What’s “alias risk”?
Multiple strings referring to the same brand/site (e.g., name variants, URL vs. brand). We apply normalization; you can extend it.
Can I use this commercially?
Check the licenses in the repo/dataset. Contributions welcome.
Do you have a tool version I can run?
You can run your own projects on SEO Vendor’s platform. For more information on RankLens, the free AI Brand Visibility tool, visit this page.