


If you’re deep in SEO, you already feel it: visibility is no longer a ranking problem alone. It’s a selection problem—selection into the answer, into the citation set, into the recommendation set, into the brand narrative.
That’s why I’m bullish on GEO audits that look “overbuilt” compared to classic SEO checklists. The uncomfortable truth is that AI visibility is an emergent property of multiple subsystems operating together:
- Retrieval eligibility (can the system fetch you?)
- Candidate selection (do you make the shortlist of sources?)
- Attribution/citation choice (do you get credited?)
- Summarization fidelity (does it describe you correctly?)
- Answer dominance (do you become the “default” source repeatedly?)
Most SEO workflows measure (2) indirectly through SERP rank. GEO requires you to measure and influence all five.
That’s why we need to view GEO in terms of modules and extensions. They’re mapping metrics to control points in that pipeline.
The core idea: treat AI engines like a noisy retrieval + synthesis stack
Whether it’s Google’s AI Overviews, Perplexity, or a browsing-enabled assistant like ChatGPT, the architecture tends to rhyme:
- A query (or prompt) gets expanded or decomposed
- A retriever selects documents (from index + web + “trusted” corpora)
- A ranker reorders candidates based on relevance + authority + freshness + intent fit
- A generator writes an answer and chooses what to cite (or not)
- Output gets post-processed for safety/policy constraints
The modules: what each one controls in the pipeline
You can’t control the model. You can control the probability distribution of whether your brand and pages:
- enter the candidate set,
- survive re-ranking,
- become the citation anchor,
- and are summarized correctly.
That’s what the metrics are for.
Module A: Baseline “What do engines say today?”
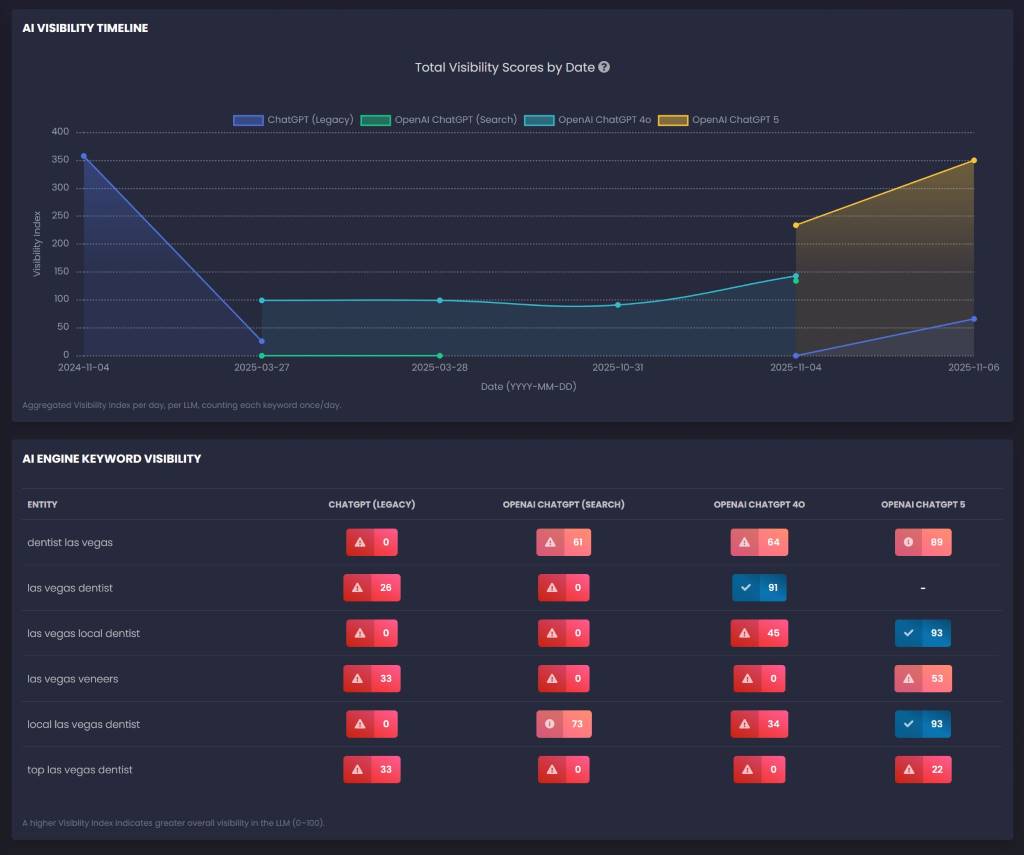

Why it exists: AI visibility is volatile. You need an empirical baseline because assumptions fail.
What it controls: You can’t optimize without a starting point. This is how you measure lift (mentions, citations, accuracy drift, competitor overlap).
Metrics that matter:
- Mention rate (per prompt cluster)
- Citation rate (per engine)
- Accuracy score (brand facts, offers, locations, pricing, disclaimers)
- Source overlap / churn (how often citations change)
Influence on GEO: This is your north star. Tools like RankLens tells you whether content changes actually change the output distribution. Without it, you’re doing vibes-based GEO.
Module B: Technical “AI accessibility” audit
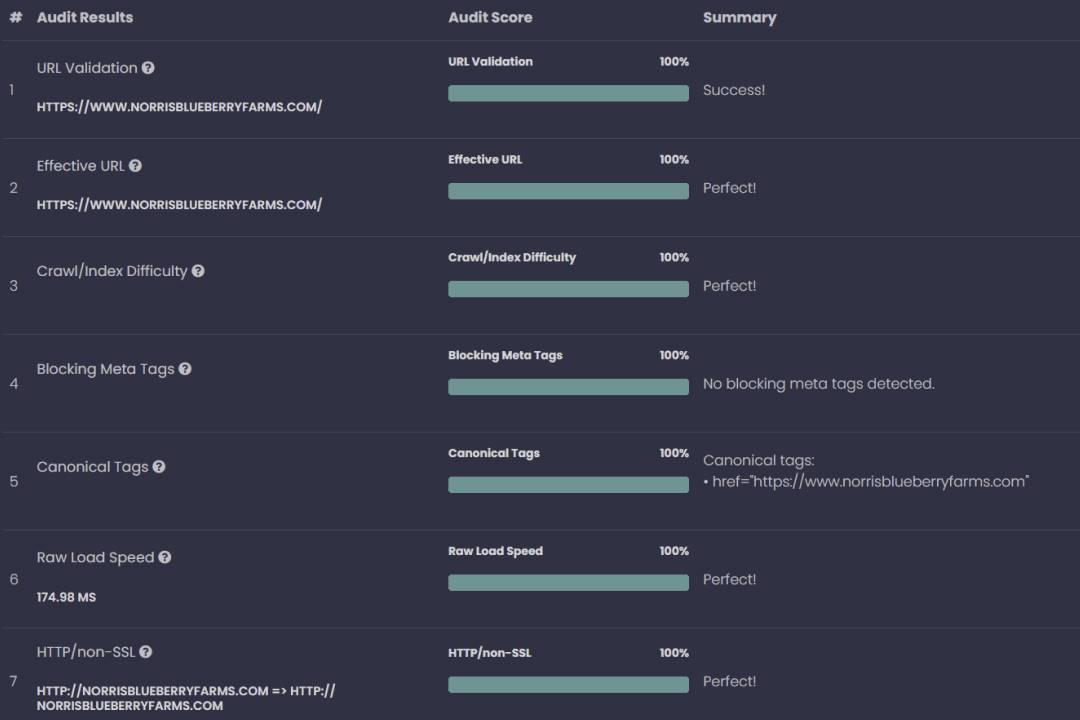
Why it exists: If AI systems can’t reliably fetch/render your content, the rest is irrelevant.
What it controls: Eligibility and stability in retrieval.
Metrics that matter:
- Crawl/render reliability (server responses, JS rendering pitfalls)
- Blocking rules (robots/meta/x-robots, WAF quirks)
- Canonicalization and duplication (which version is “the” page)
- Performance thresholds (timeouts kill candidacy)
Influence on GEO: You don’t win citations if you don’t get fetched. Technical issues don’t just reduce traffic; they reduce existence in the retrieval layer. Analyze with traditional SEO tools like Preliminary Audit.
Module C: Content Extractability & Answer Quality
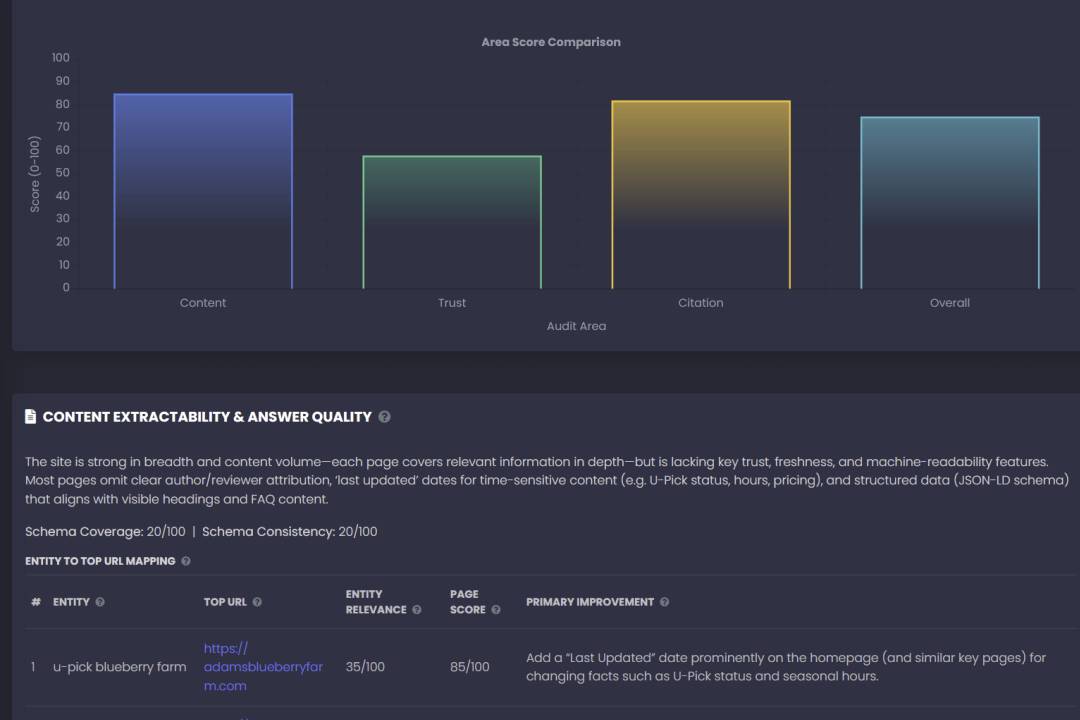
This is the first place where GEO diverges sharply from SEO.
Why it exists: AI engines don’t “read” like humans. They excerpt. They compress. They stitch. They prefer content that is quotable.
What it controls: Whether your page becomes the cleanest answer artifact in the candidate set.
Key metrics (and what they really measure):
- Direct answer presence: Is there an obvious 2–4 sentence snippet that solves the prompt?
→ Increases probability of being used verbatim or paraphrased. - Question heading density: Is the page structured as Q → A blocks?
→ Matches prompt decomposition, improves chunk selection. - Lists/tables: Can the model safely summarize without hallucinating?
→ Tables and checklists reduce ambiguity and boost fidelity. - Internal linking structure: Does the site demonstrate topical completeness and relationships?
→ Helps entity/topic graph coherence; improves intent coverage. - Outbound citations: Are you grounding claims in authoritative sources?
→ Improves trust in sensitive topics; reduces “risky summary” penalties. - Freshness signals: Is it safe to assume the info is current?
→ Re-ranking often prefers recent/updated info for time-sensitive facts.
Influence on GEO: Extractability raises the chance you become the “path of least resistance” source. AI systems love the document that answers cleanly with minimal rewrite risk.
Module D: Trust Signals & Entity Clarity
This is where “E-E-A-T” becomes operational instead of philosophical.
Why it exists: In a world of generated text, trust is inferred from structure, identity, and verification signals—not from vibes.
What it controls: Whether your brand/page is treated as a reliable authority, and whether the system can disambiguate you from similarly named entities.
Key metrics (and what they really measure):
- Organization identity completeness (name/address/phone/service area):
→ Reduces entity ambiguity; improves correctness in summaries. - Author/reviewer attribution:
→ Improves credibility in YMYL; reduces safety risk. - Governance pages (policies, editorial guidelines, corrections):
→ Signals accountability and reduces “low-trust publisher” inference. - Proof assets (awards, case results, benchmarks, testimonials):
→ Helps win “why should I choose X?” prompts (recommendation prompts). - Consistency checks (NAP across pages and profiles):
→ Prevents the worst GEO failure: AI says the wrong phone/address.
Influence on GEO: Trust metrics move you up in re-ranking and reduce the likelihood you’re excluded for uncertainty. They also improve accuracy—often the overlooked “visibility multiplier” because wrong summaries reduce conversion even when you’re mentioned.
Module E: Off-site Citation Surface
This is where many SEOs realize the game moved outside their site.
Why it exists: AI systems frequently cite sources that are not the “best page,” but the most corroborated page.
What it controls: External validation and competitive parity in the citation ecosystem.
Key metrics:
- Profile completeness across major directories/maps/reviews
- Review velocity and richness (not just stars; language that matches intents)
- Media/PR citations (especially local + niche authoritative outlets)
- Community footprint (threads where the audience asks real questions)
- Competitor citation patterns (what sources repeatedly show up in answers)
Influence on GEO: This increases the probability that when the model “checks reality,” it finds your brand consistently across multiple surfaces. It’s also how you compete for recommendation prompts, where the answer engine may lean heavily on third-party proof.
Module F: Recommendations & Prioritized Roadmap
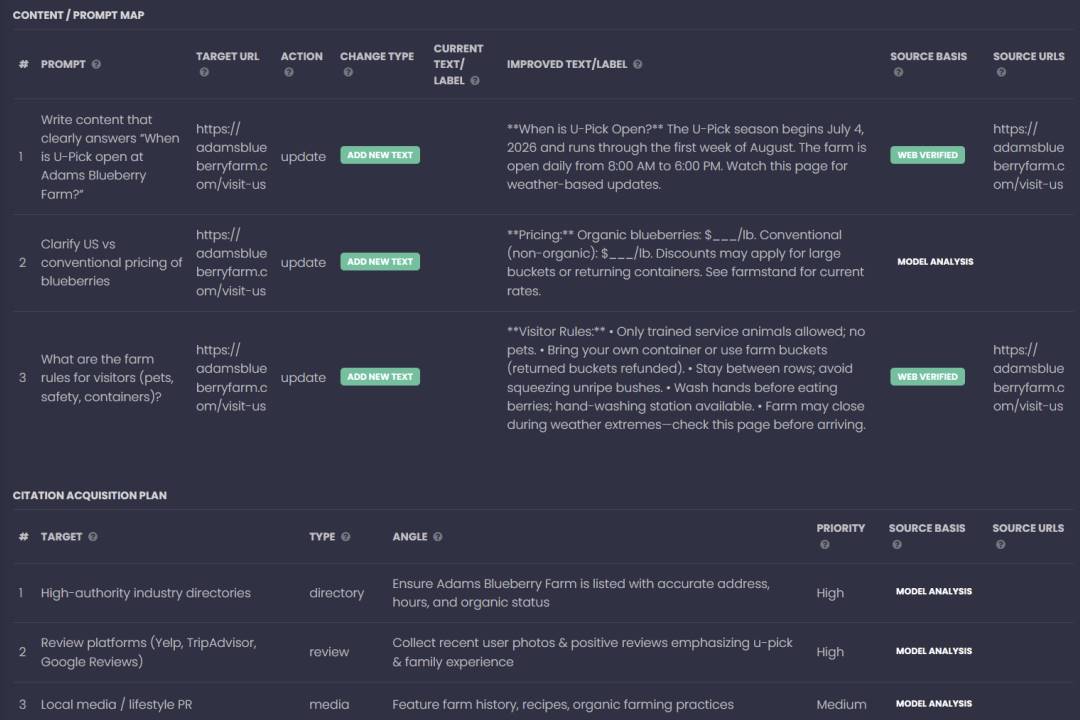
A GEO audit without prioritization is just an expensive spreadsheet.
Why it exists: AI visibility is a compounding system. You need sequencing: fix the foundations first, then scale.
What it controls: Execution efficiency—getting the biggest lift with limited time.
Key metrics:
- Opportunity scoring (relevance × gaps in extractability/trust/schema)
- Owner mapping (Dev vs Content vs Outreach vs Legal)
- Time-window planning (Weeks 1–2 vs 30–90 days vs 180 days)
- Retest plan (how to verify impact)
Influence on GEO: The roadmap is your “experiment design.” It ensures you change variables in a way you can measure and repeat.
Extensions: the “advanced levers” that separate amateurs from operators
1) Intent Coverage & Multi-Canonical Mapping
Why it exists: One entity often needs multiple best pages because prompts come in modes:
- definition (“what is…”)
- transactional (“hire/buy/near me”)
- comparison (“vs/alternatives”)
- proof (“reviews/results/outcomes”)
Metric rationale: A single “best URL” creates blind spots. AI engines will source each intent from different page archetypes.
Influence on GEO: Proper intent canonicals reduce dilution and cannibalization in the AI candidate set. You stop asking one page to be everything.
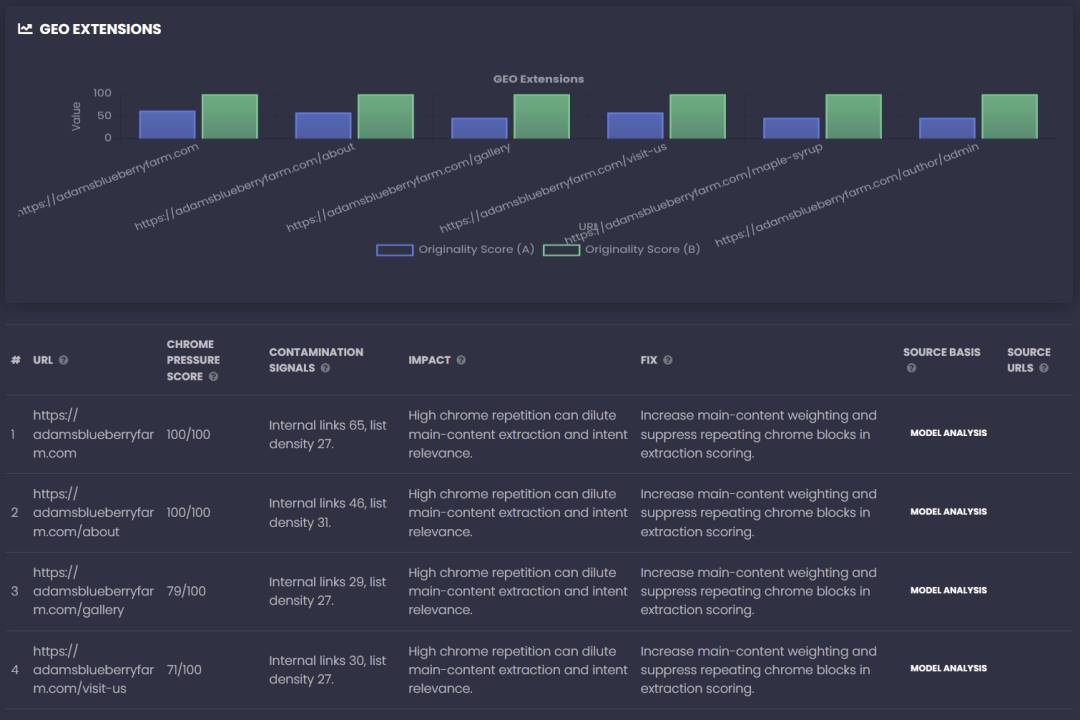
2) Cite-worthiness & Boilerplate Controls
Why it exists: Many pages “rank” but aren’t citeable. Also, template chrome can drown out main content signals.
Metrics that matter:
- Originality/artifact score: do you have quote-ready objects (tables, checklists, benchmarks, timelines, process steps, calculators)?
- Chrome pressure score: how much nav/footer/sidebar boilerplate contaminates extraction?
Influence on GEO: Artifact-rich pages are easier for models to reuse. Boilerplate control prevents the system from over-weighting repeated template text and misidentifying topical focus.
3) Entity Graph Completeness & Citation-Native Surfaces
Why it exists: AI systems don’t just read pages—they build internal entity representations. If your graph is incomplete, you lose on disambiguation and trust.
Metrics:
- completeness across GBP/Apple Maps/Bing/LinkedIn/industry registries
- citation-native owned surfaces (FAQ hubs, docs, pricing/service scope pages)
Influence on GEO: Strong entity graphs reduce hallucinated brand facts and make your brand “snap into place” across engines. Citation-native surfaces become repeatable citation anchors.
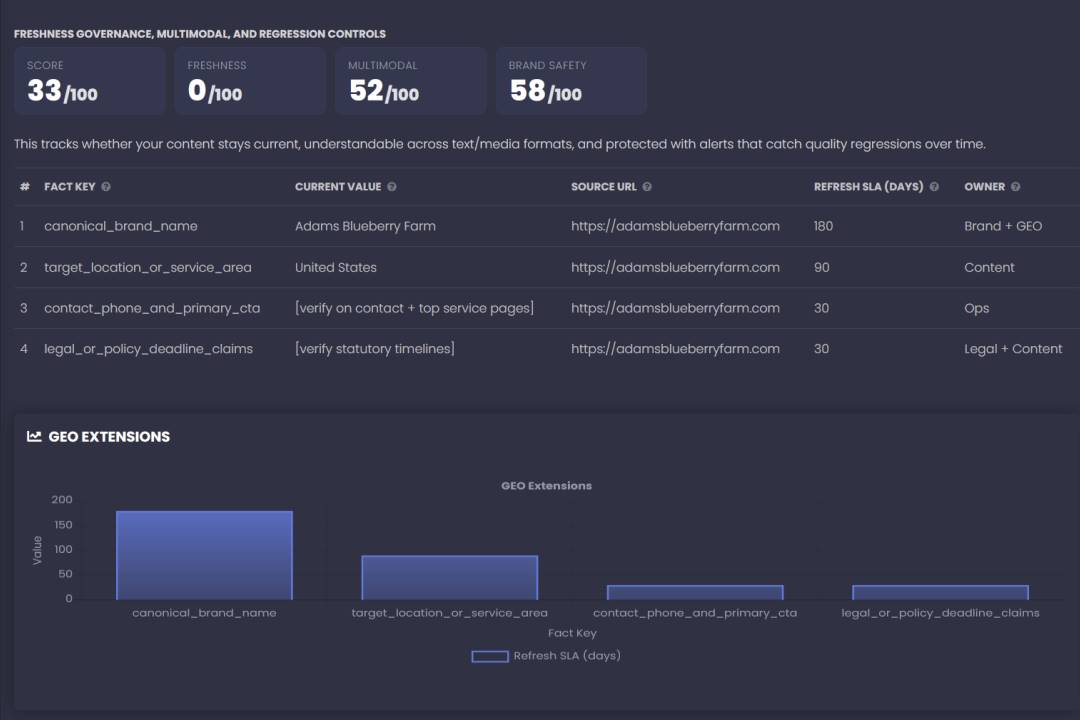
4) Freshness Governance, Multimodal Readiness, Brand Safety
Why it exists: The fastest way to lose GEO gains is stale facts, non-text media gaps, or risky claims.
Metrics:
- facts registry + SLAs (phones, deadlines, pricing, policies)
- multimodal extractability (alt text, captions, transcripts, HTML equivalents for PDFs)
- brand safety readiness (scope clarity, correction pathways, disclaimers)
Influence on GEO: Freshness increases re-ranking preference; multimodal improves extractability; brand safety reduces suppression/avoidance and summary errors in sensitive topics.
5) Regression Controls (Monitoring)
Why it exists: GEO isn’t “set and forget.” Engines drift. Sites drift. Templates change.
Metrics:
- canonical drift (winner page changes across runs)
- schema integrity drops
- authorship/credibility signal loss
- freshness SLA breaches
- citation-native surface staleness
Influence on GEO: Monitoring protects your gains. Without it, your visibility becomes a random walk.
Why these metrics matter: they correspond to controllable probabilities
Here’s the thought-provoking claim:
GEO is probability engineering.
Every metric is a proxy for one of these probabilities:
- P(retrieved) — you entered the candidate set
- P(selected | retrieved) — you survived ranking/re-ranking
- P(cited | selected) — you became attributable
- P(accurate | cited) — the summary matches reality
- P(recommended | accurate) — you’re framed as the best choice
Classic SEO mostly optimizes P(retrieved) via rank. GEO optimizes the full chain.
The trap experts fall into: optimizing relevance when you should optimize safety
In the AI era, the best source isn’t only “relevant.” It’s “safe to use”:
- safe because it’s structured
- safe because it’s current
- safe because identity is clear
- safe because claims are bounded and supported
- safe because third-party corroboration exists
Your competitors might not have better content. They might simply be safer to cite.
The most practical takeaway for GEO/SEO experts
Build pages that answer like a checklist, prove like a dossier, and corroborate like a Wikipedia entry.
That’s what the modules and extensions collectively enforce.
If you’re already running GEO experiments, the next level is to stop thinking “optimize page,” and start thinking “optimize the system”: intent canonicals, artifacts, entity graph completeness, freshness governance, and monitoring.
Because the new competitive edge isn’t ranking.
It’s becoming the default source the answer engine reaches for—again and again. Assess these modules and extensions on your sites with GEO Audit.