The use of large language models (LLMs) for generating business recommendations is a growing field of interest, particularly as these models are adapted to serve specific consumer needs, like providing lists of businesses based on a given prompt. In this in-depth study, we examine how ChatGPT-4o, a model based on OpenAI’s GPT-4o, performs in generating lists of businesses under different prompting conditions, focusing specifically on a prompt centered on “best dentists in Las Vegas”.
Table of Contents
The objective involves a process we created call multi-sampling, by which we iterate a prompt multiple times to take “snapshots” to track and measure businesses. As well as how the presence or absence of web-browsing capabilities and variations in prompt phrasing affect the quality, consistency, and accuracy of the business recommendations provided by the LLM.
The study was conducted using custom-built software tools designed to analyze ChatGPT-4o responses across different configurations. The results provide insights into how LLMs like GPT-4o can be leveraged to make informed business recommendations under different operational conditions.
Experimental Design
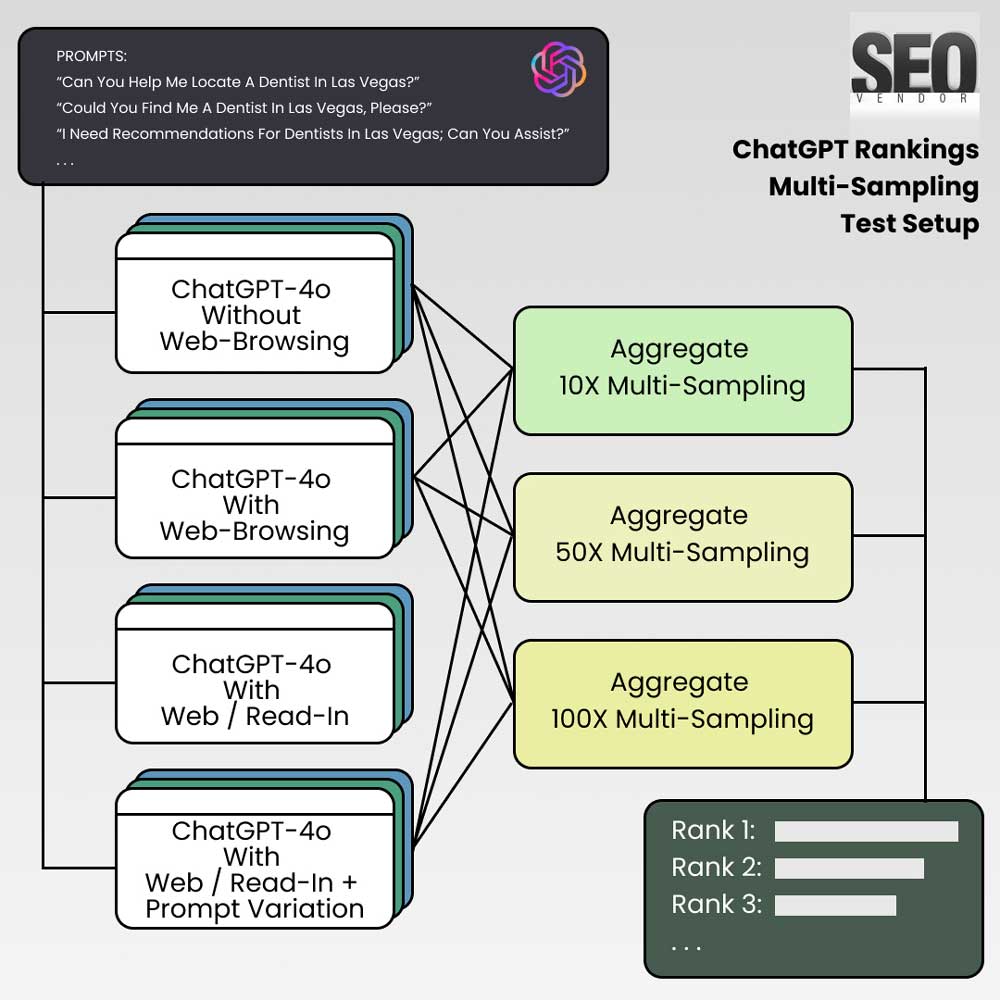
The study used a series of experiments involving four conditions under which ChatGPT-4o was prompted to generate a list of recommended businesses (in this instance, dentists in Las Vegas). The conditions were as follows:
- ChatGPT-4o Without Web-Browsing (Free ChatGPT): In this condition, GPT-4o was used without any access to real-time web data or browsing capabilities. The model generated responses based solely on the information present in its training data.
- ChatGPT-4o with Web-Browsing Search (Paid ChatGPT): Here, GPT-4o was equipped with access to web-browsing capabilities via Bing. This allowed it to supplement its training data with real-time information, theoretically enabling it to provide more accurate and up-to-date recommendations.
- ChatGPT-4o with Web-Browsing Read-In (SearchGPT): In this condition, GPT-4o was not only able to perform a web search but also capable of reading specific articles and web pages, such as “Top Dentists in Las Vegas”. This additional read-in ability was designed to help the model provide recommendations based on direct data retrieval from relevant pages.
- ChatGPT-4o with Web-Browsing Read-In + Prompt Variation (SearchGPT): In this scenario, the model was tested using ten slightly different versions of the prompt. Each version asked for recommendations about dentists in Las Vegas in varied phrasing, from “Can you help me locate a dentist in Las Vegas?” to “Could you search for dentists practicing in Las Vegas?”. The purpose of using prompt variations was to test how the model’s responses differed depending on the wording and to evaluate the impact of subtle changes in phrasing on the consistency and reliability of the output.
Why Run This Experiment?
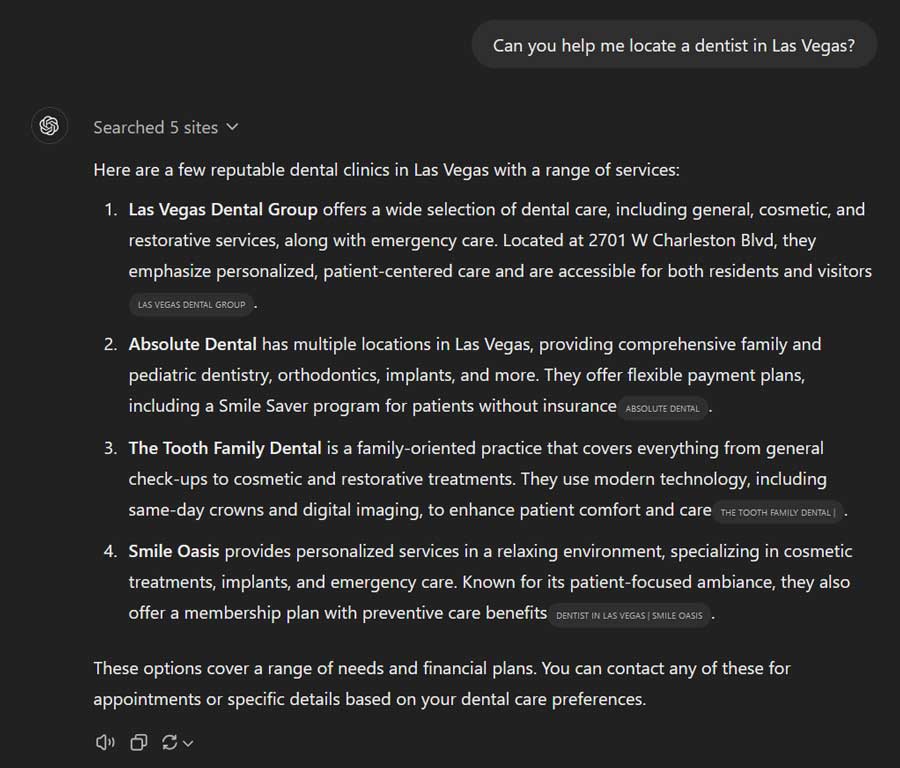
ChatGPT—and soon-to-be-integrated SearchGPT—have the potential to disrupt how we find and search for brands and businesses. We noticed a lack of information online testing how well large language models understand brands, businesses, and their associated websites.
Given that Google, at the time of this writing, has a market capitalization of $2.06 trillion, and ChatGPT is the fastest-growing platform in history, it is likely that as more people use OpenAI to find answers, businesses will become more interested in the commercial potential of LLMs.
While we believe search engines will likely remain with us, it’s difficult to assess the potential for marketing on LLM platforms without the valuable insights conducting experiments like this can bring.
Business Potential
Large language models like ChatGPT learn from a vast knowledge library. As such, we considered the ease of finding a brand like “Nike” versus smaller businesses that are less likely to be known. In the US alone, there are 33 million businesses, according to the U.S. Small Business Administration.
- If, hypothetically, 10% of these businesses are found using ChatGPT (with SearchGPT), that would be 3.3 million businesses. These include large and small businesses, whether they are Fortune 500 companies or mom-and-pop stores.
- According to The Verge, as of August 2024, ChatGPT has over 200 million weekly active users, doubling from 100 million in November 2023.
- We can project out the growth of ChatGPT users taking into account technological advancements, competition, and market saturation.
- At this rate, by 2029, 20% of all businesses in the US will be impacted by 493 Million ChatGPT users.
Business Potential of ChatGPT
| Year | User Count (Millions) | SearchGPT Businesses Found |
Business Impact (%) |
| 2024 | 200 | 3300000 | 10 |
| 2025 | 260 | 3795000 | 12 |
| 2026 | 325 | 4364250 | 13 |
| 2027 | 390 | 5018887 | 15 |
| 2028 | 448 | 5771721 | 17 |
| 2029 | 493 | 6637479 | 20 |
From these projections, we decided on the local Las Vegas market, focusing solely on dentists in the area, as we predict it will likely be among the 20% of businesses impacted by 2029.
By focusing on a localized service market, we can also more thoroughly assess the knowledge capabilities of ChatGPT. This approach can show how millions of businesses might, in the future, view ChatGPT or similar LLMs as an opportunity to acquire new clients and customers.
Prompt Variations
The prompt variations included in the fourth condition were designed to simulate natural ways in which users may seek similar information. They included:
- “Can you help me locate a dentist in Las Vegas?”
- “Could you find me a dentist in Las Vegas, please?”
- “I need recommendations for dentists in Las Vegas; can you assist?”
- “Please search for a dentist located in Las Vegas.”
- “Could you point me to a dentist in the Las Vegas area?”
- “I’m looking for a dentist in Las Vegas; can you help me find one?”
- “Can you look up a Las Vegas dentist for me?”
- “I need a dentist in Las Vegas; could you find one?”
- “Can you find a reputable dentist in Las Vegas for me?”
- “Could you search for dentists practicing in Las Vegas?”
Prompts were always independently tested, meaning these is no residual memory between each test or sampling.
Multi-Sampling Strategy
Each of the four conditions was tested with multiple samples to ensure consistency and reliability of the results. Specifically, GPT-4o was prompted:
- 100X: Sampling was tracked for100 iterations.
- 50X: Sampling was tracked for 50 iterations.
- 10X: Sampling was tracked for 10 iterations.
This resulted in a total of twelve different experiments (3 multi-samples × 4 conditions), yielding over 5,700 rows of data for analysis. The data was extracted, compiled, and thoroughly analyzed to determine patterns, accuracy, consistency, and variations in responses across the different conditions.
How We Tracked a Business
In all of our tests, we measure both the brand and website signatures. We validate brands and websites to ensure they are real and not hallucinated by the AI. While most hallucinated results were removed, in some aggregate graphs, we intentionally did not exclude 1-2 generic or made-up businesses to demonstrate their ranking appearance. In these circumstances, we identify these anomalies to compare their frequency of appearance with that of real businesses.
Rank Definition in ChatGPT
We then defined ranking in ChatGPT on a first-appearance basis. The output provided was usually in natural sentence format, with results represented in a list, providing the business name and the website (if available).
Chatbots like ChatGPT use prompt-based inputs and generally provide text answers in the form of structured text, unlike search engines, which traditionally define search results in a list format.
Since the questions we ask are about dentists in Las Vegas, ChatGPT provided multiple answers, structuring them into a list for us.
Version of GPT
All tests were conducted with chatgpt-4o-latest The model version always connects to the latest version of GPT-4o used in ChatGPT, The final test runs were conducted in September and October of 2024. Future results may vary as ChatGPT-4o is frequently updated.
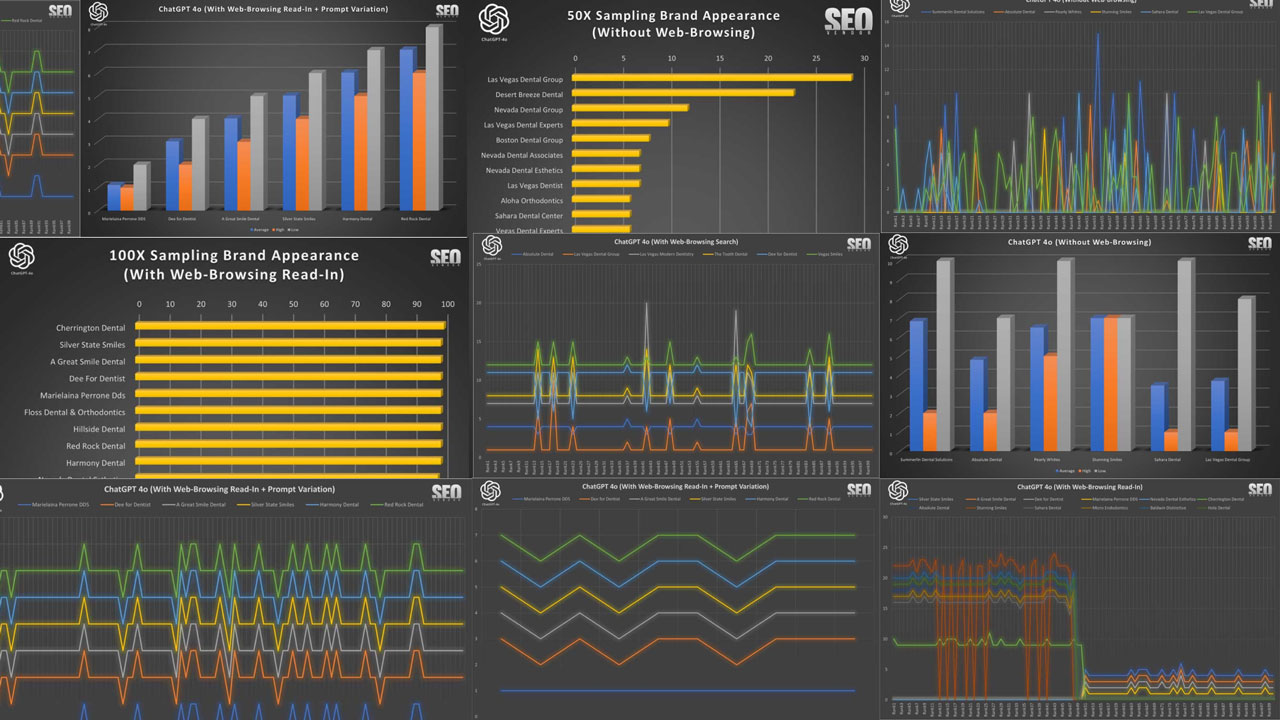
Results from 50X Iteration Sampling
The purpose of this test was to acquire the appearance of a business, a dental practice in this instance, by prompting 50 times and measuring the resulting appearance of business names and their website. Tests were conducted with a custom-built business and website validation tool, that evaluated each name and website returned by the AI.
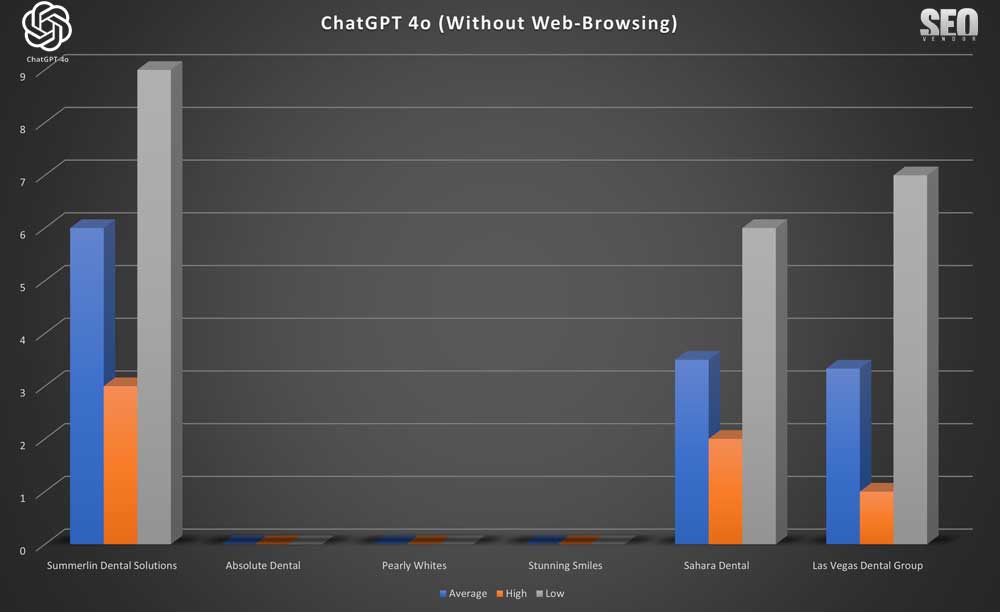
50X ChatGPT Without Web-Browsing
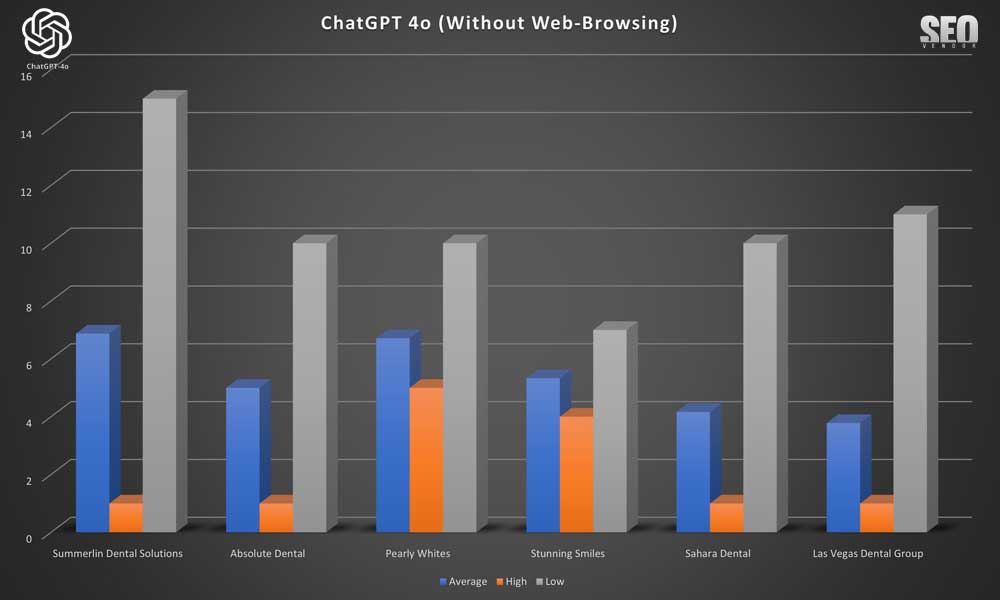
Brand Appearance for 50 Samples Without Web-Browsing (Chart 1): This chart illustrates the overlap in brand recommendations in the absence of browsing for 50 samples, showing repeated business names in each sample. The y-axis corresponds to the rank position of a brand appearing from a list returned by GPT-4o, whereas the x-axis shows the runtime iteration.
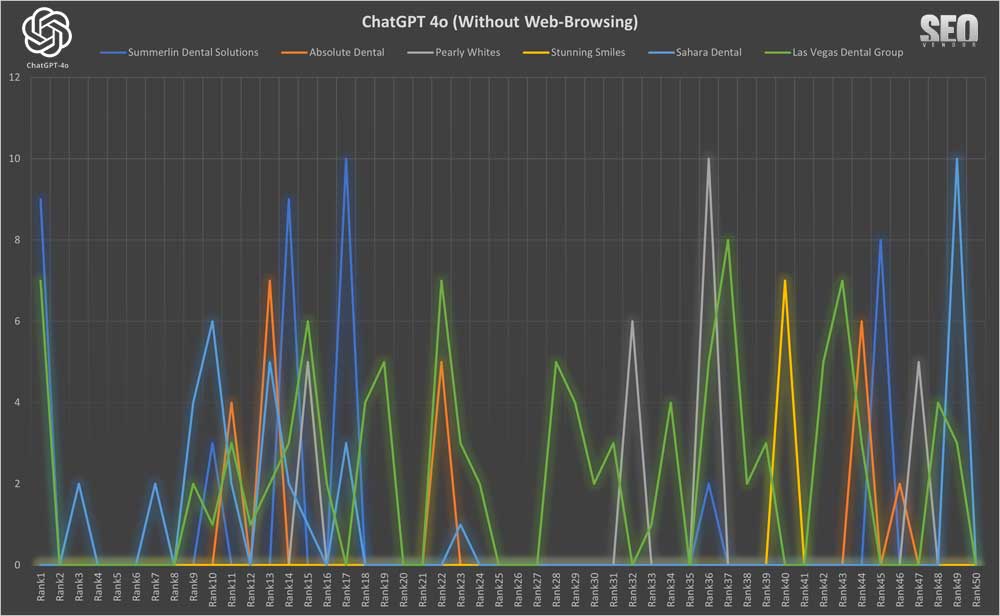
We can see that the appearance of a brand, in 50 iterations, appears quite scattered, with no apparent cohesion between a brand and how GPT-4o lists them in results. Here, a rank is determined as the position on the list of results returned by GPT-4o. A business that ranked high in one iteration can be ranked low or non-existent in the next iteration.
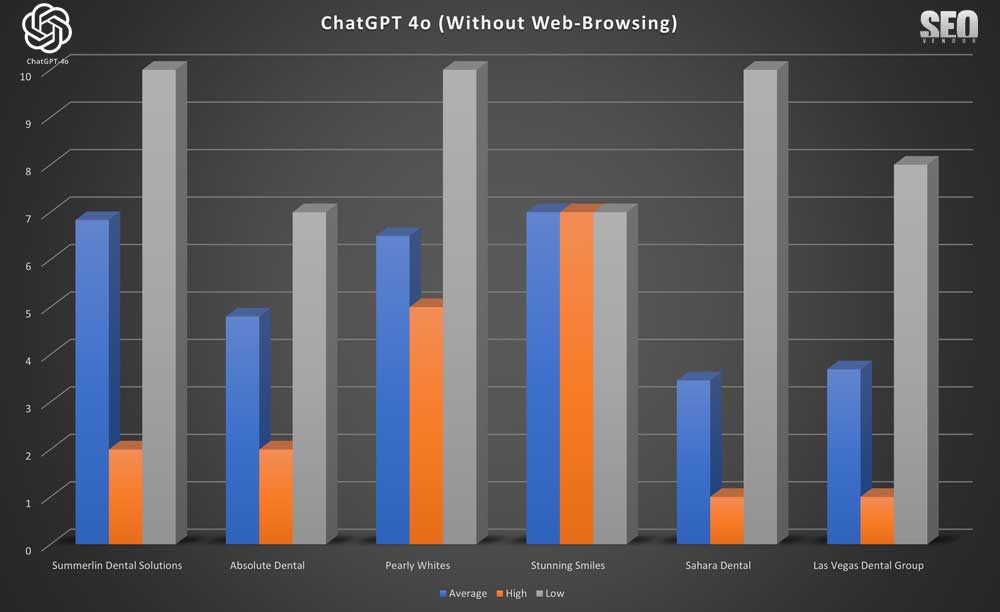
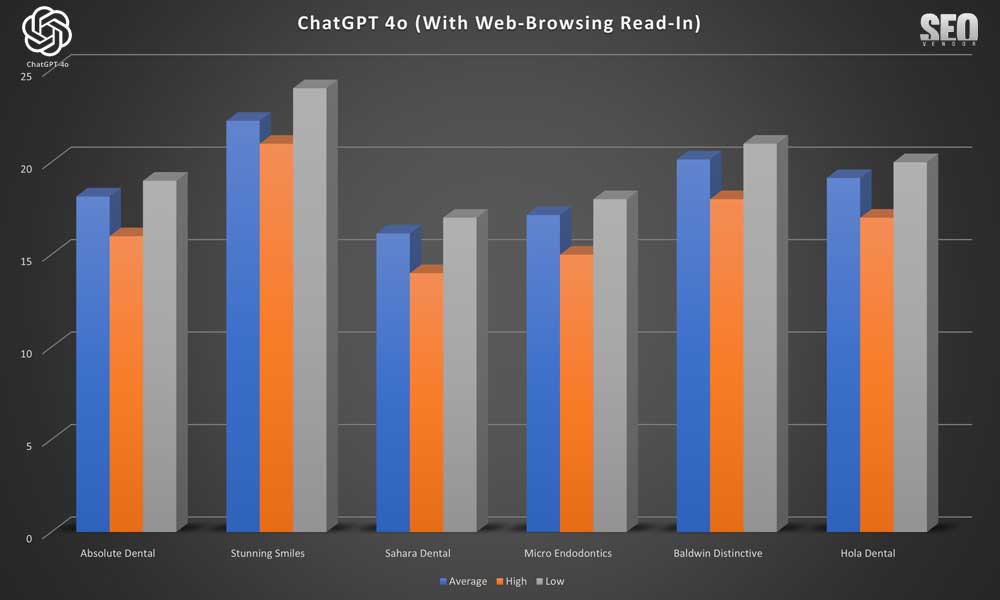
In Chart 2, we compare the rankings (average, high, low) of six randomly selected brands. We see that there is a wide discrepancy between high and low rankings. There appears to be no specific order when we calculated the numbers, with any zero-values removed. Otherwise, the actual averages across 50 iterations would be much lower since the randomness in the results causes brands to appear rarely, as we can see from Chart 1. For Stunning Smiles, the average is the same as the low and high because it only appeared once in 50 iterations.
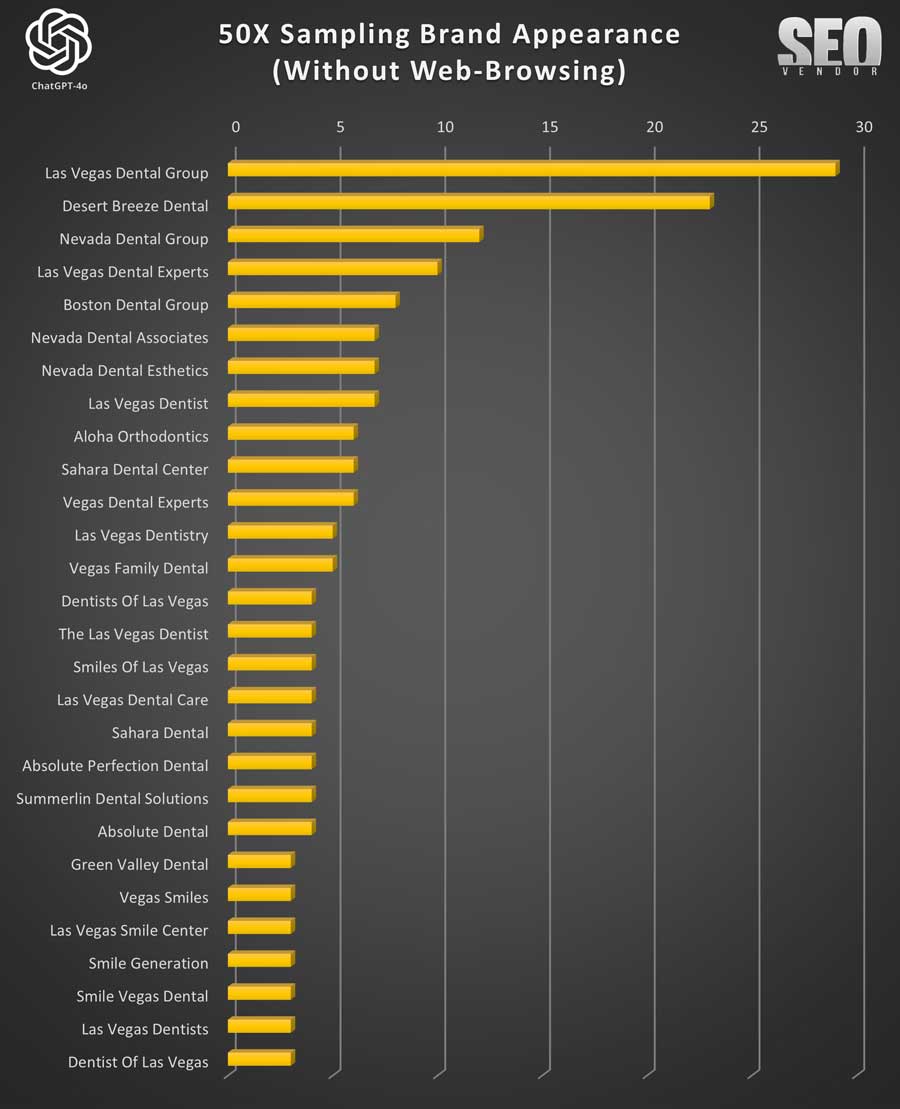
Chart 3 shows, despite the randomness, how often a site appears still results in a gradient curve, where a small number of sites appear much more frequently than most of the sites. The entire list would be much longer, but these are the top, most frequent appearances shown in the chart.
Note about hallucinations: Note that we kept “Las Vegas Dentists” and “Dentist of Las Vegas”, among others, in Chart 3 so that we can observe the frequency of fake/made-up dentist entities. Most of these fake entries were in the low single-digits and were removed during data analysis.
Real-World Applications
In practical applications, ChatGPT without web-browsing capabilities can be encountered not only through API usage but also in certain application instances. For example, when browsing is turned off, models like ChatGPT-o1, ChatGPT 3.5 or custom GPTs that have disabled web-browsing still lack access to web content (at the time of this writing). Most ChatGPT paid users will experience some level of web-browsing; therefore, we also sampled web-browsing searches below.
50X ChatGPT With Web-Browsing Search
Brand Appearance for 50 Samples With Web-Browsing Search (Chart 4): This chart shows how web-browsing influenced the variety of recommended businesses, allowing GPT-4o to provide fresher recommendations.
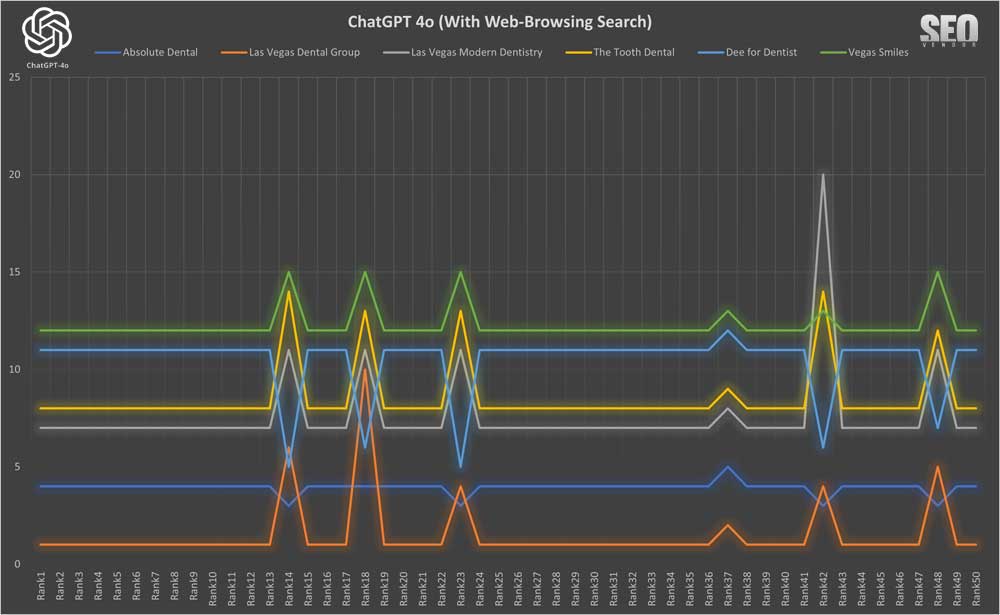
Web browsing search provides GPT-4o with Bing search results so that it has real-time data. We’ve found that giving Bing results greatly impacts the ranking of each business. We’ve observed that over 50 samples, rankings tend to be much more stable than without web-browsing, as GPT-4o takes on the results from Bing with significant weight for sites it considers in its results.
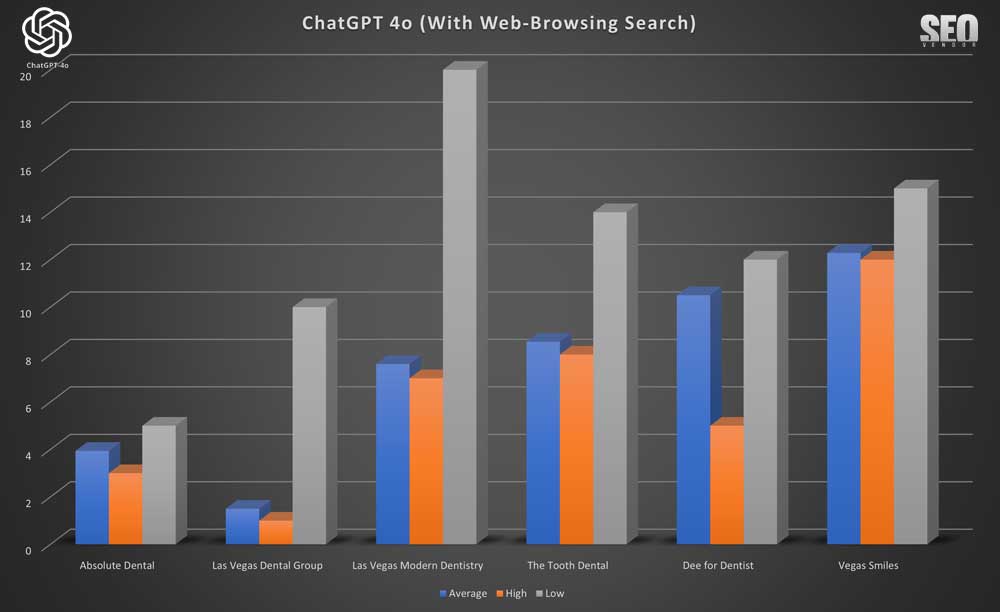
Brand Appearance for 50 Samples With Web-Browsing Search (Chart 5) highlights the positive impact of real-time data on the quality of recommendations, including businesses that are popular but may not have been in GPT-4o’s original training set. With very few exceptions, we see less change between low and high rankings, which also stabilized average positions.
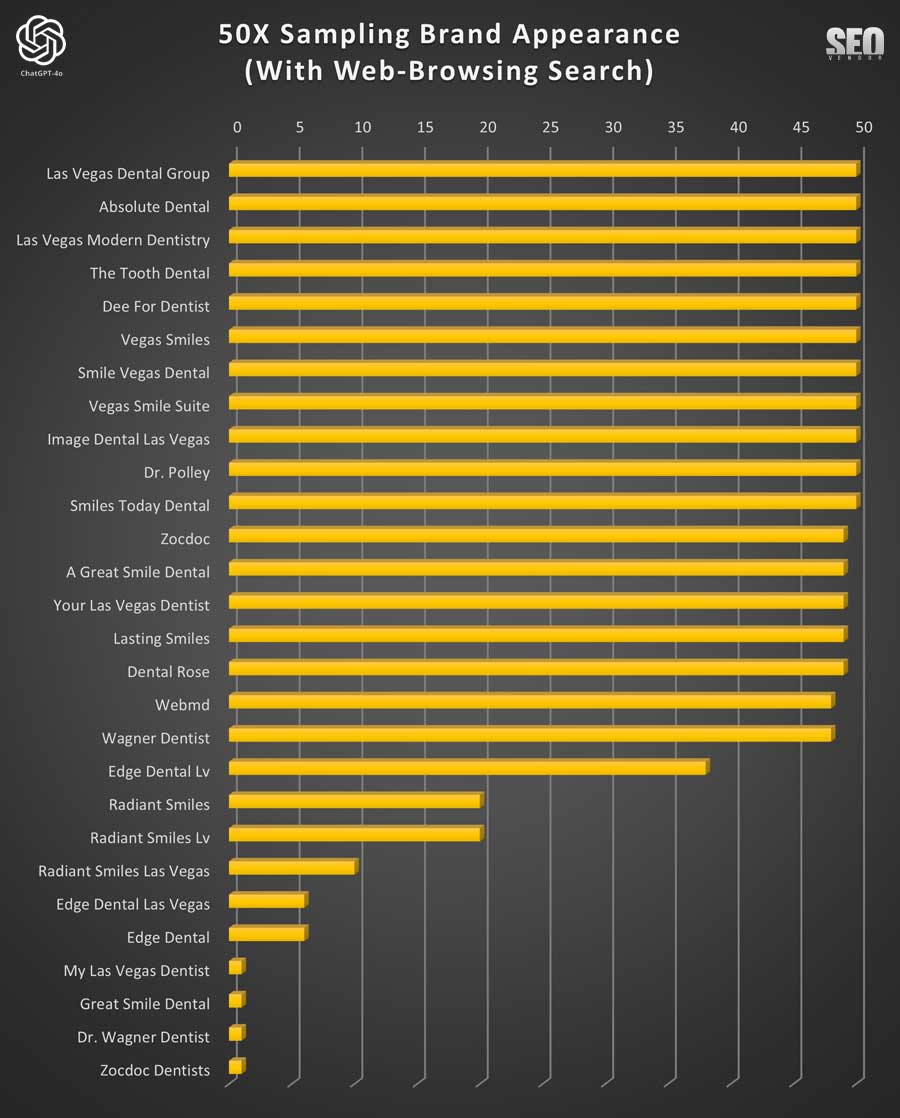
When we view the results from 50 times sampling with search results (Chart 6), we saw a dramatic fall in randomness, and a much higher degree of consistency of businesses that appear. As expected, most seem to be coming from Bing search results.
Real-World Applications
Web-browsing capabilities offer a more accurate model of how most people use ChatGPT, as adding web browsing makes a significant impact on results from newer data. However, it’s not actually the end-all, be-all, according to our findings.
ChatGPT will go one step further by reading into the search results and snippets to provide recommendations. Therefore, we also need to account for instances when it does this.
After conducting the sampling tests, we have a chart that explains how the results can be distributed among the different methods.
50X ChatGPT With Web-Browsing Read-In
Brand Appearance for 50 Samples With Web-Browsing Read-In (Chart 7): A look at how enabling Read-In helped identify niche and highly-rated businesses, which would have otherwise been missed.
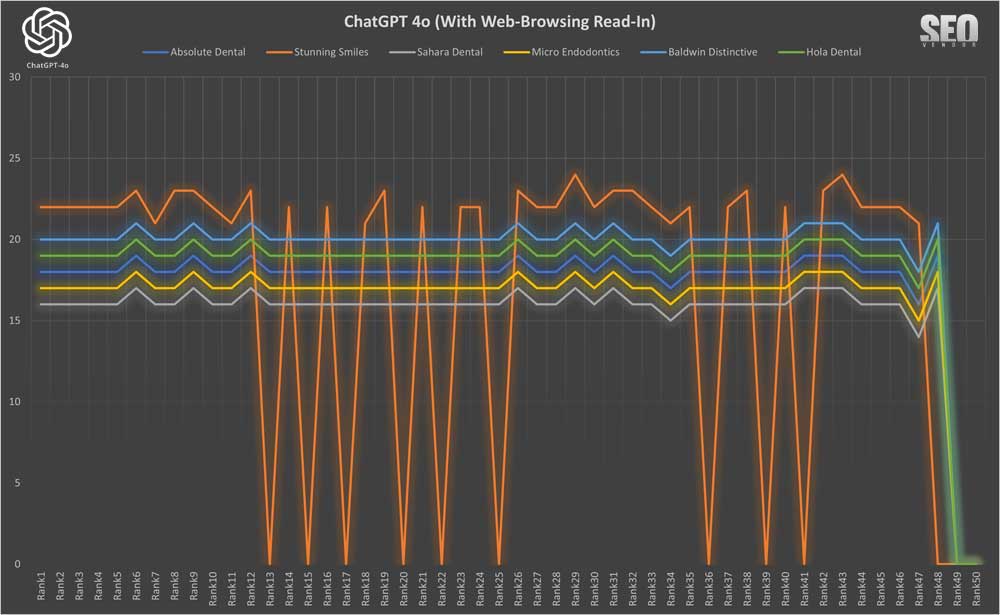
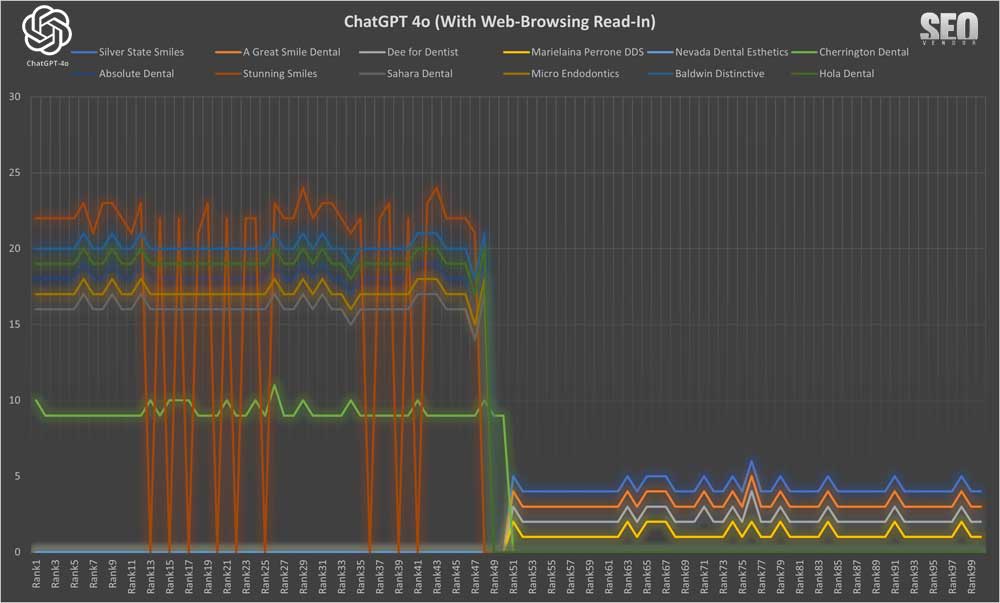
When we look at selective rankings results from web-browsing Read-In, we saw a similar consistency with only web-browsing. Notice once of the samples, “Stunning Smiles”, dropped completely out of rankings from time to time.
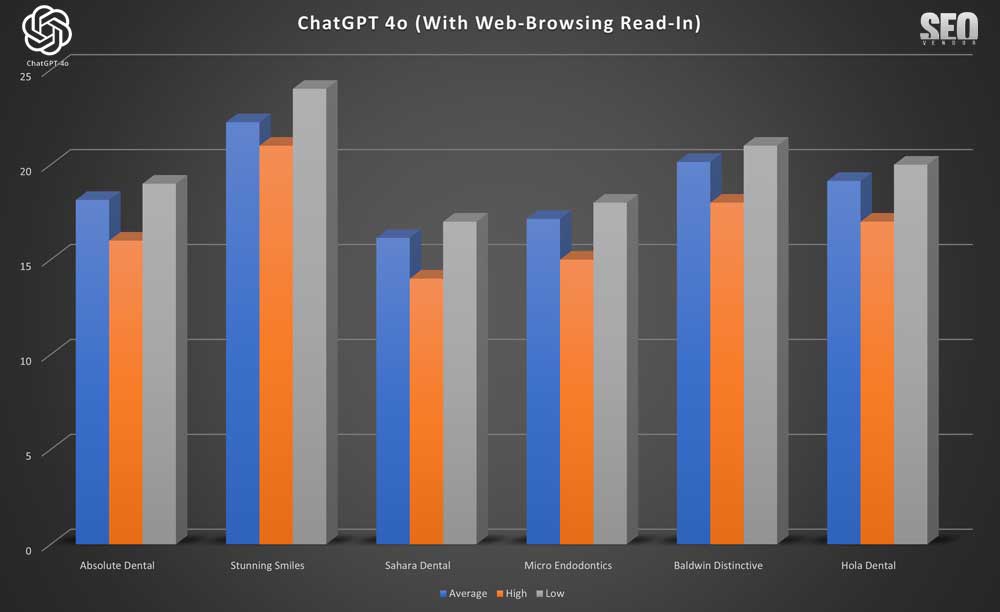
Brand Appearance for 50 Samples With Web-Browsing Read-In (Chart 8) shows specific mentions of niche dentists and their consistency across samples, in both high and low rankings. In all the tests, we found Read-In to provide the most consistent averages given that we did not count iterations where ranking was non-existent.
The chart below provides a better idea of frequency of appearance, whereas Chart 8 focus on how often a business appeared when there were rankings.
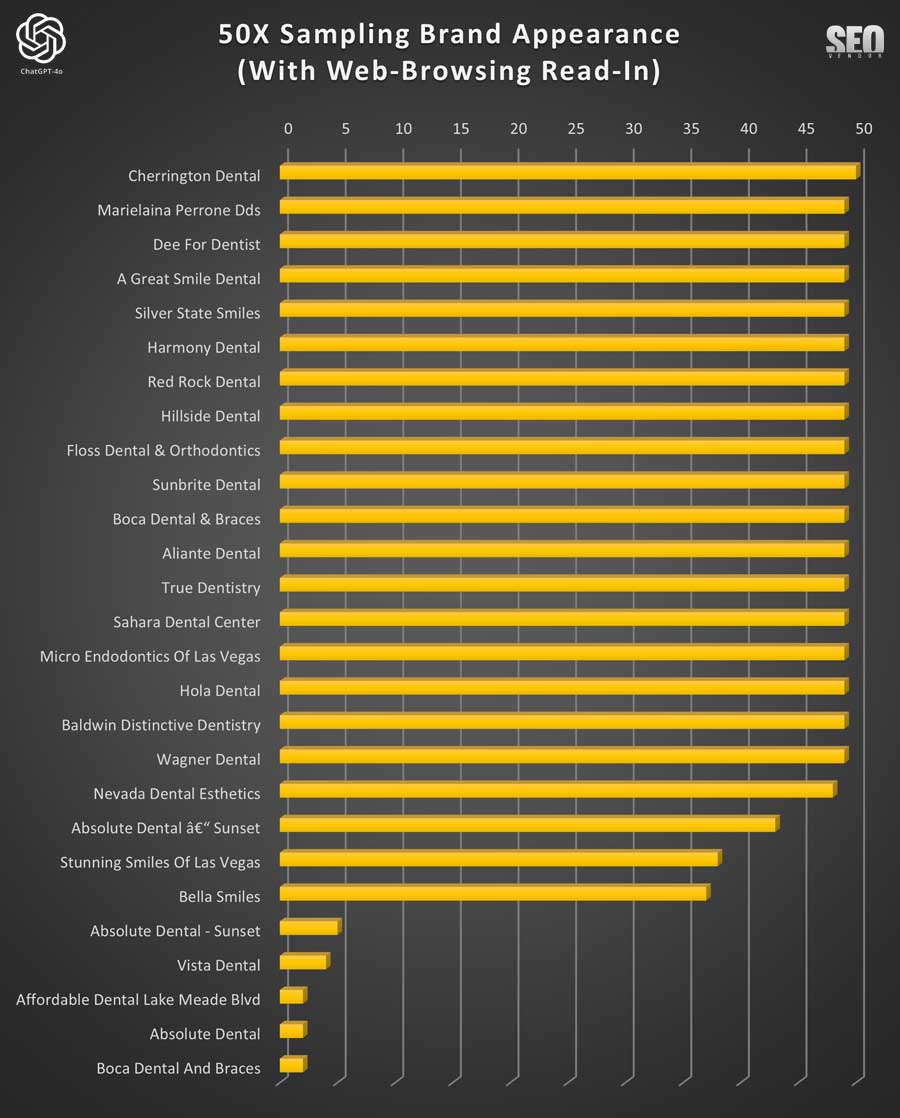
Most brand that appeared in Chart 9, consistently re-appeared across nearly all 50 iterations. There were a few outliers where the brand name returned by ChatGPT did not meet our brand similarity threshold of 90%. Thus, some of them, for example Absolute Dental and Boca Dental will appear more than once.
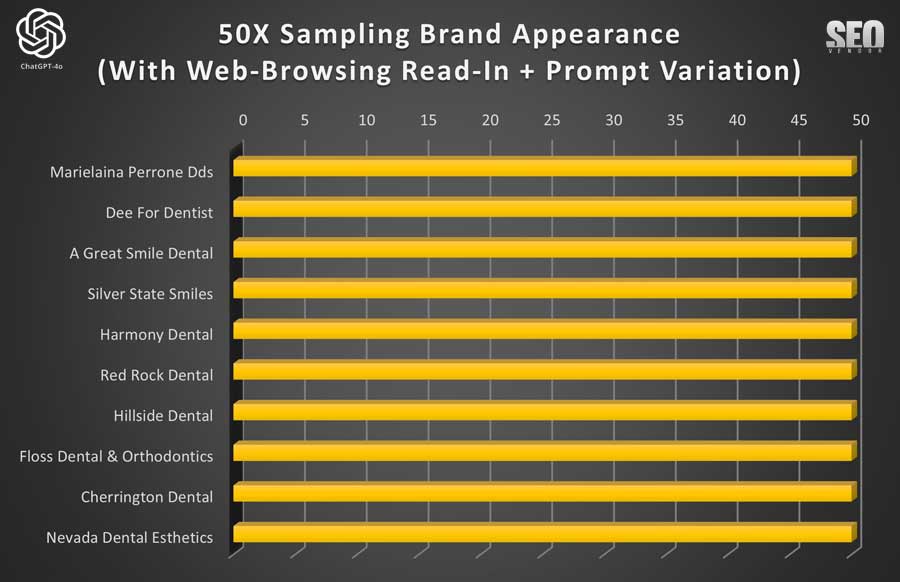
50X ChatGPT Web-Browsing Read-In + Prompt Variation
Brand Appearance for 50 Samples With Web-Browsing Read-In + Prompt Variation (Chart 10): Demonstrates how prompt variations allowed GPT-4o to potentially diversify its responses however, in our case, these we witnessed little to almost no impact to results. Much to our surprise, variations (at least in the manner we presented them), did not result in a broader range of dentist recommendations.
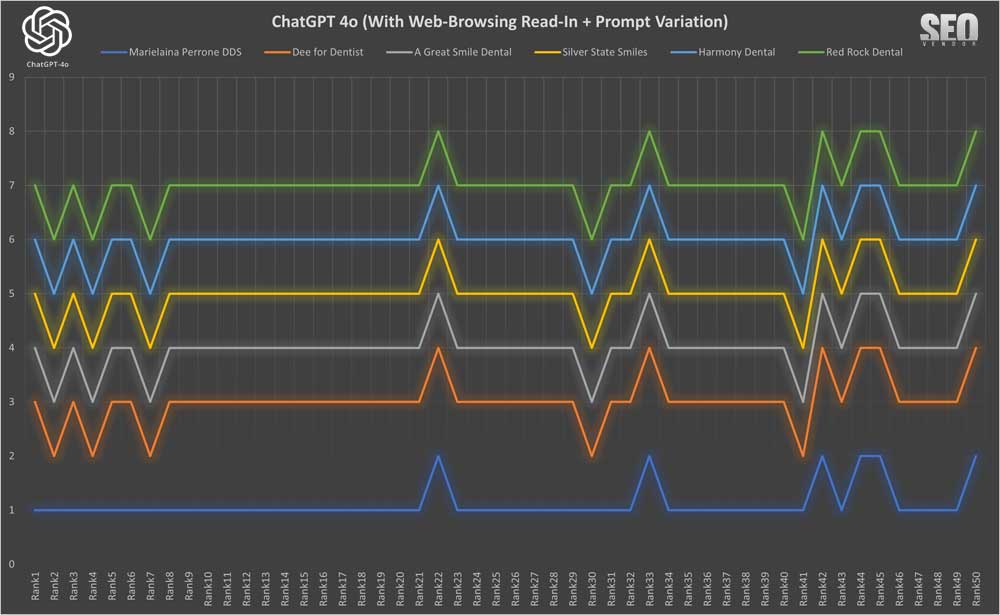
Instead, most businesses stayed in their positions. However, a vastly different set of dentists were recommended. However, those recommendations more or less stayed at the same rank despite prompt differences. Our theory is there may be some underlying cache at OpenAI that may be looking at similar prompts, or perhaps at matching similar results. However, there’s no way for us to determine that for certain.
Brand Appearance for 50 Samples With Web-Browsing Read-In + Prompt Variation (Chart 11): A further analysis of how minor prompt phrasing influenced the recommended business. In a surprising turn of events, prompt variations did not increase variation in results, but actually limited down the possible results.
We investigated into this and found that prompt variation itself would have to be greatly different for there to be variation differences. Hence, changes in phrasing did not impact the results (Chart 12), as long as the meaning is the same. If changing a word changes the meaning, then the results would be entirely different. On the other hand, saying the same thing in a different manner didn’t change the results.
What did happen was that results appear to have no “drop-off” at all as each prompt variation was ran 10 times, those 10 did not result in any further deviation in the results.
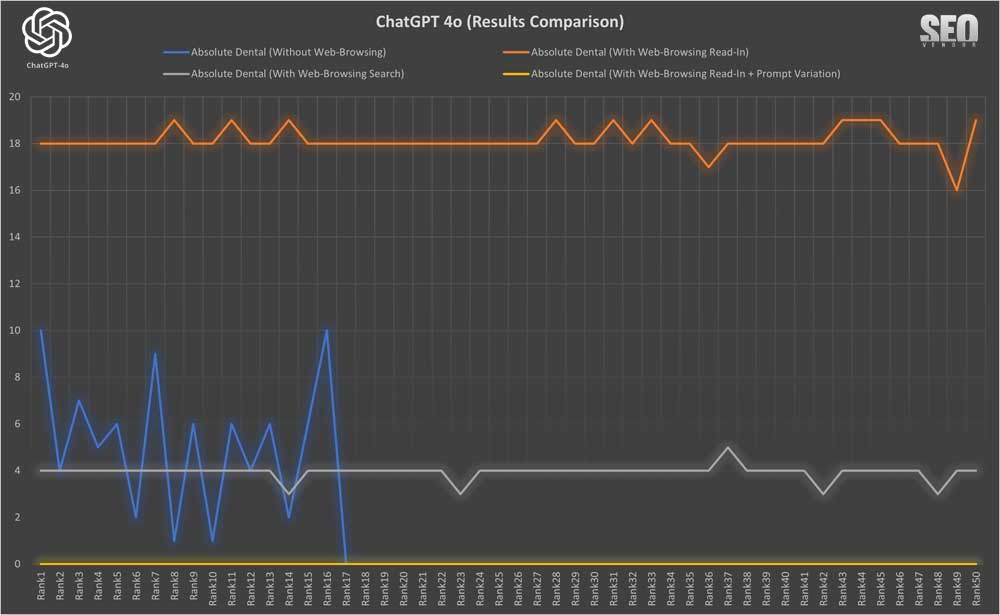
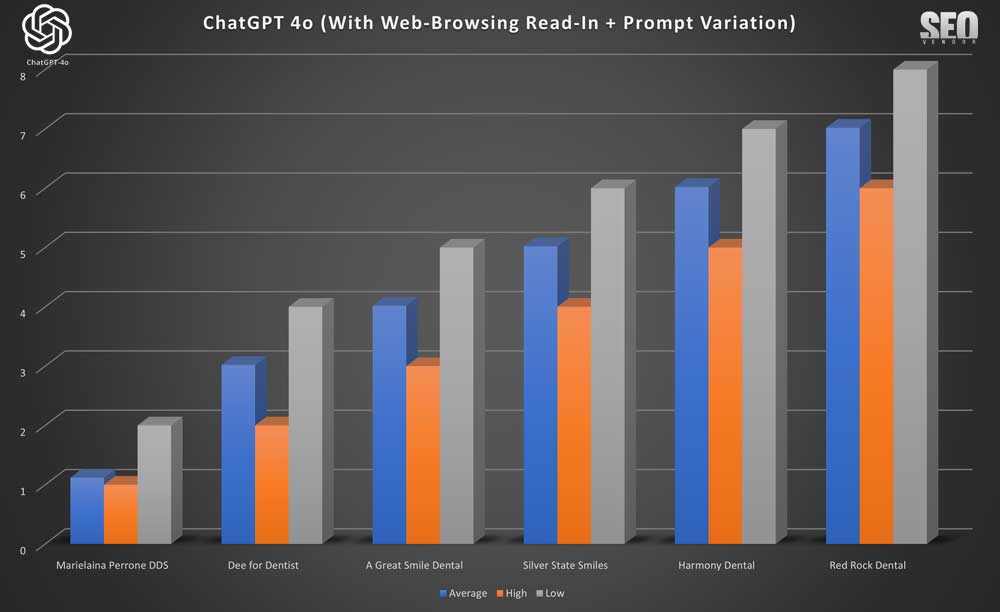
To dig a bit deeper, we wanted to compare all 4 experiment methods for a brand that appeared frequently, so we chose Absolute Dental. Results in Chart 13 showed that web-browsing rankings remained steady across sampling tests that included web-browsing, but since prompt variation did not result in any rankings for Absolute Dental, we compared an additional dental practice in its place in Chart 14 below.
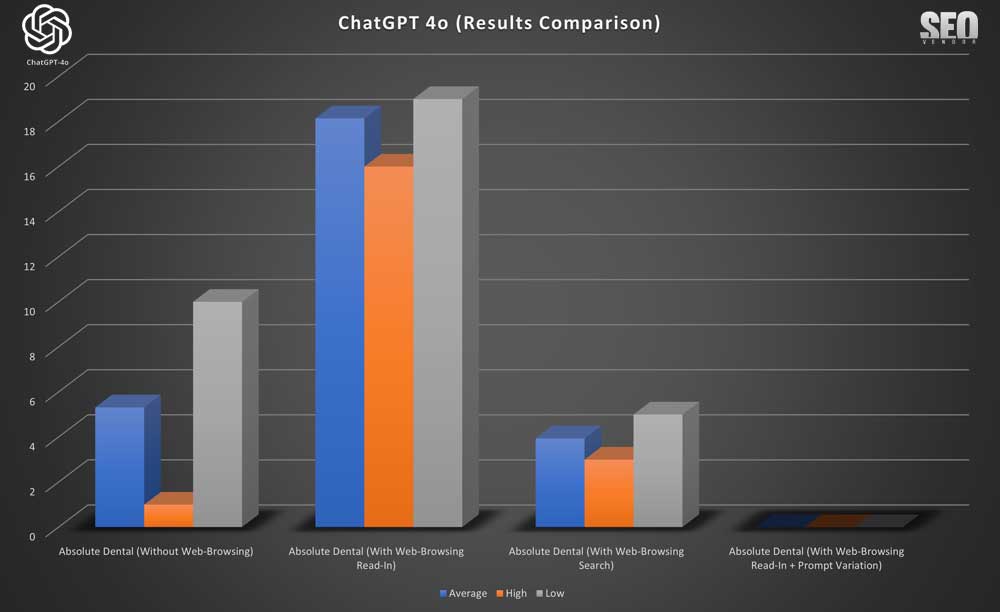
We found that a brand can experience greater stability through iterations if web-browsing was activated, but rankings can be significantly different depending on the search results or information from Read-In. Whereas, if web-browsing was deactivated, then variations in ranking in each iteration can occur.
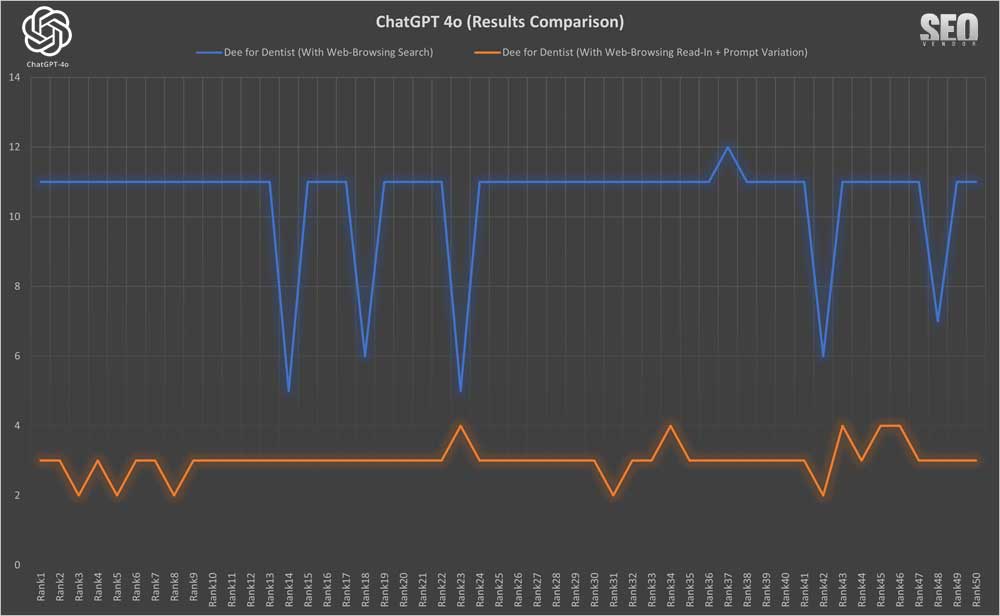
When we compare browsing search with Read-In + prompt variation, we find that the results in Chart 15 are similar, further proving that results from prompt variations that don’t impact meaning, also won’t bear any significant weight on rankings.
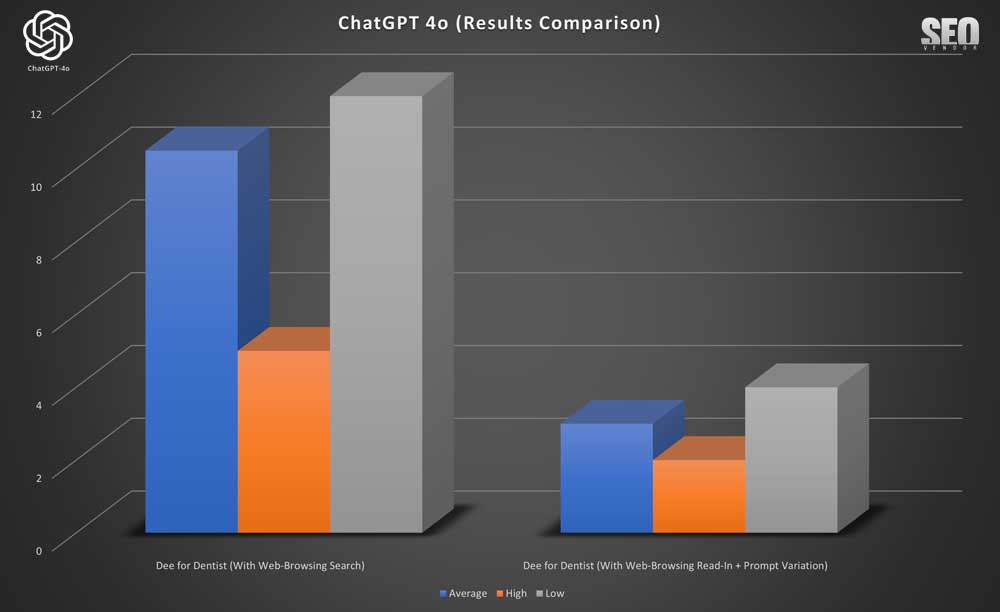
We can see that web-browsing (with Read-In+ prompt variation) in the case of Dee for Dentist (Chart 16) result in higher rankings compared to browsing search. However, it could have been just as true that rankings with prompt variation went down or dropped completely as was the case with Absolute Dental.
Key Findings for 50 Samples
- Less Brand Overlap in Non-Browsing Condition:
- “Without Web-Browsing” exhibited a fewer overlap in recommended brands, such as “Absolute Dental” and “Las Vegas Dental Group,” consistent across the multiple prompts.
- Indicates limited access to RAG (Retrieval-Augmented Generation) information sources, resulting in greater variation in outputs.
- Less Diversity in Brands with Web-Browsing Search:
- When GPT-4o used web-browsing search capabilities, the model’s recommendations narrowed to businesses like “The Tooth Dental” and “Las Vegas Modern Dentistry.”
- Highlights the importance of real-time access to web searches in influencing the model’s responses.
- Prompt Variation and Business Diversity:
- With prompt variations combined with web-browsing, the diversity in the recommendations actually decreased.
- Specific brands such as “Dee for Dentist” and “Silver State Smiles” appeared prominently, suggesting that phrasing did not impact the range of businesses recommended as long as meaning was the same.
- Emphasis on Popular Names:
- Across all conditions, “Absolute Dental” appeared consistently, regardless of browsing capabilities or prompt variations.
- This suggests an inherent bias towards well-known brands that persists even when real-time browsing is enabled.
- Effect of Web-Browsing Read-In:
- “With Web-Browsing Read-In” produced more specific brand recommendations.
- Providers like “Cherrington Dental” and “Red Rock Dental” were highlighted, showing that the ability to read specific web content led to recommendations that were more aligned with reviewed or featured dentists.
- Accuracy in Brand Names:
- The browsing-enabled conditions provided more accurate and complete business names.
- Compared to the “Without Web-Browsing” condition, there were fewer inaccuracies or generic labels like “Las Vegas Dentist.” This suggests the web-browsing feature effectively minimizes errors related to business names.
- Comparison Charts Show Consistency with Browsing Capabilities:
- The charts comparing results across different conditions indicate that browsing (both search and read-in) provides more consistency in responses across multiple prompts, with fewer outliers and more frequent mentions of top-rated dental offices.
- Repetition Increased with Browsing:
- There was more repetition in the businesses recommended when browsing capabilities were enabled.
- For instance, names like “Las Vegas Dental Group” appeared more frequently across samples when web-browsing was used, showing that the model accessed a narrow range of sources.
Results from 100X Iteration Sampling
Our most extensive research involved testing 100 iterations of sampling with ChatGPT. While we don’t expect anyone to use prompts this way in a practical manner, the process helps us understand the reliability and variance in how ChatGPT supplies answers.
By running 100 iterations, we were able to gain valuable insights into ChatGPT that were not possible with shorter runs.
100X ChatGPT Without Web-Browsing
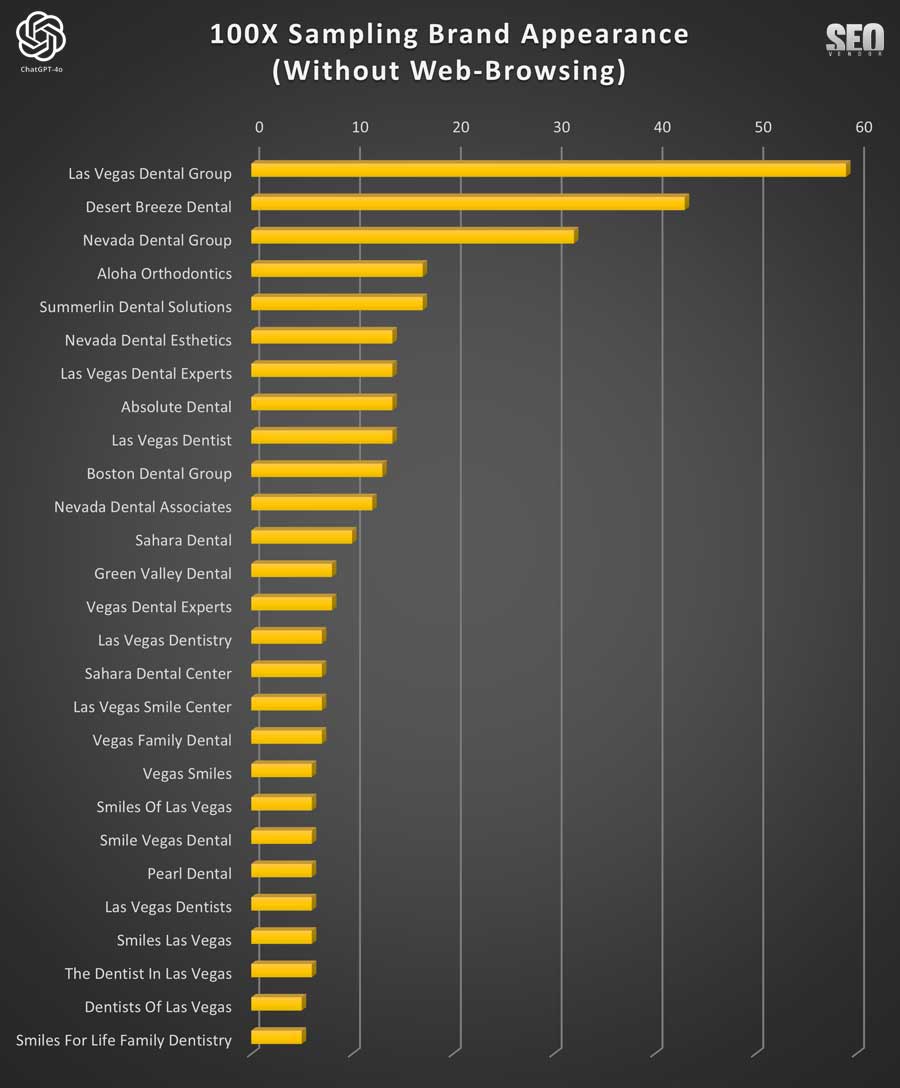
First, we ran the Brand Appearance for 100 Samples Without Web-Browsing (Chart 17). This chart illustrates the frequency of business brand recommendations when GPT-4o was used without any web-browsing capabilities. It highlights the repetition and overlap of selected brands and how often they appeared.
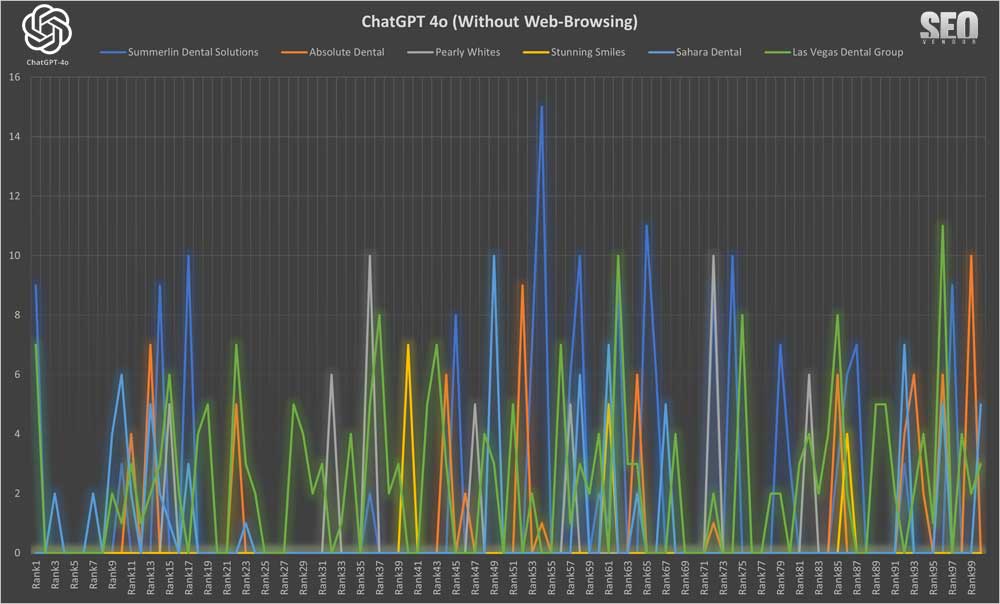
We can determine from this that the scattering of business visibility, high variance in rankings, and also the appearance of rankings itself (or lack of) were distributed throughout the sampling tests. Furthermore, it indicated that without web-browsing, GPT-4o by itself needed a large sample pool to determine the likelihood of a business appearing.
In Chart 18, we observe the variation in brand recommendations across 100 samples without web-browsing capabilities. It shows the most frequently recommended brands and how consistently they appear across different prompts.
Note: One important observation was the increase in hallucinated brands or websites that appeared during the 100X sampling. In our tests, we validated all businesses and intentionally included in the chart the aggregated top results—even those like “The Dentist in Las Vegas” and “Dentists of Las Vegas”—to observe their frequency of appearance.
In Chart 19 we observed that based on ChatGPT’s internal training knowledge, there was inherent bias towards certain businesses. This is apparent by the number of times each business appeared after given the same prompt.
100X ChatGPT With Web-Browsing Search
Chart 20 shows Brand Appearance for 100 Samples With Web-Browsing Search. This chart demonstrates the businesses recommended by GPT-4o when web-browsing search capabilities were enabled, showcasing increased uniformity compared to the non-browsing condition.
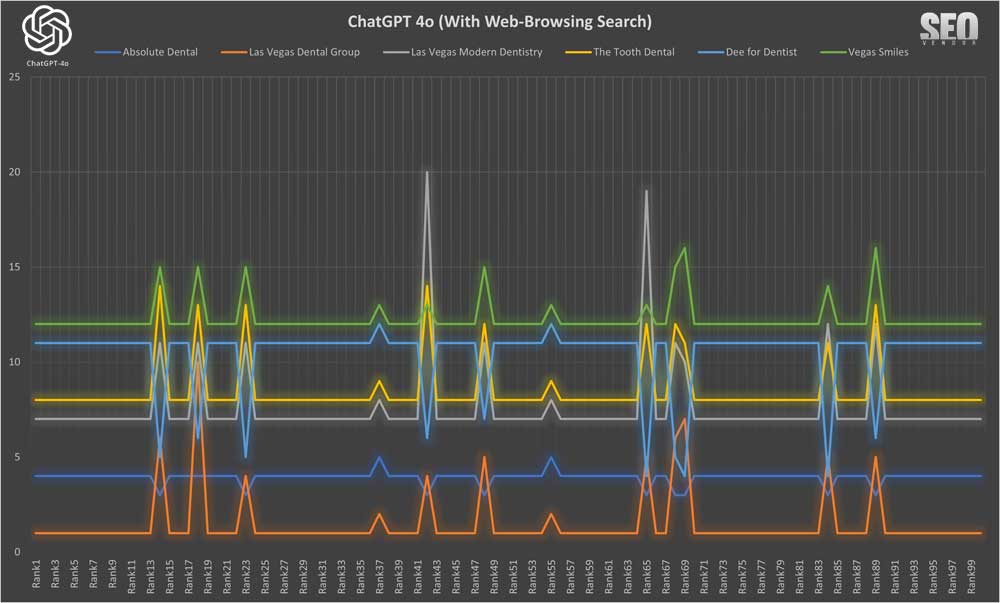
We can see that longer iterations for sampling Web-Browsing Search did not result in much difference from sampling 50X. The detailed visualization of the brand position across 100 samples highlighted (Chart 21) shows how certain brands can still dominate ChatGPT appearance. In some cases, we also saw a big swing between a brand’s top and lowest rankings.
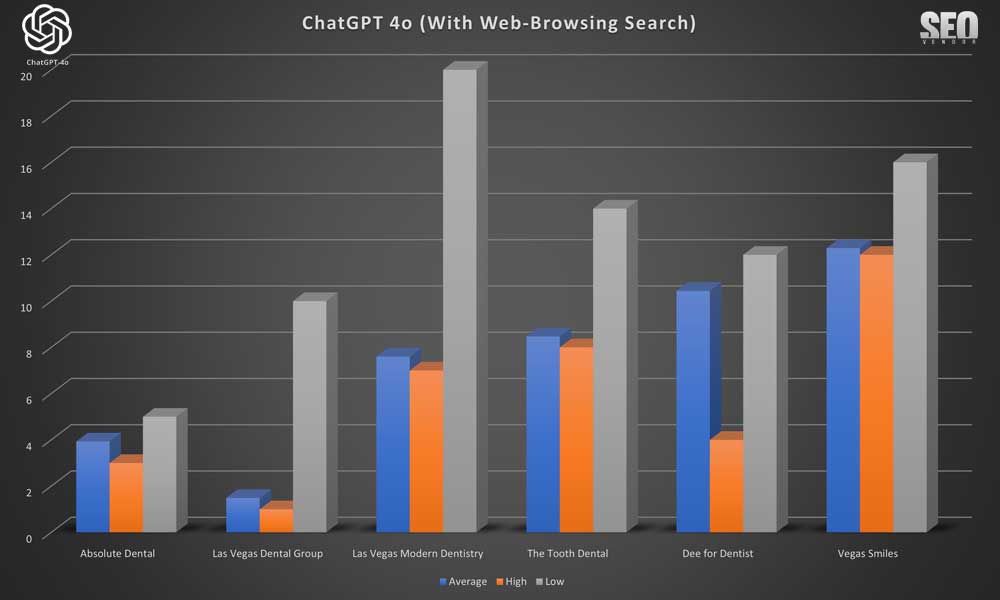
We can also observe that, interestingly, the businesses with the best average rankings are also the ones that dominate near the top of the appearance chart (Chart 22). It demonstrates that lower rankings, in the case of web-browsing search, also impacts frequency of appearance.
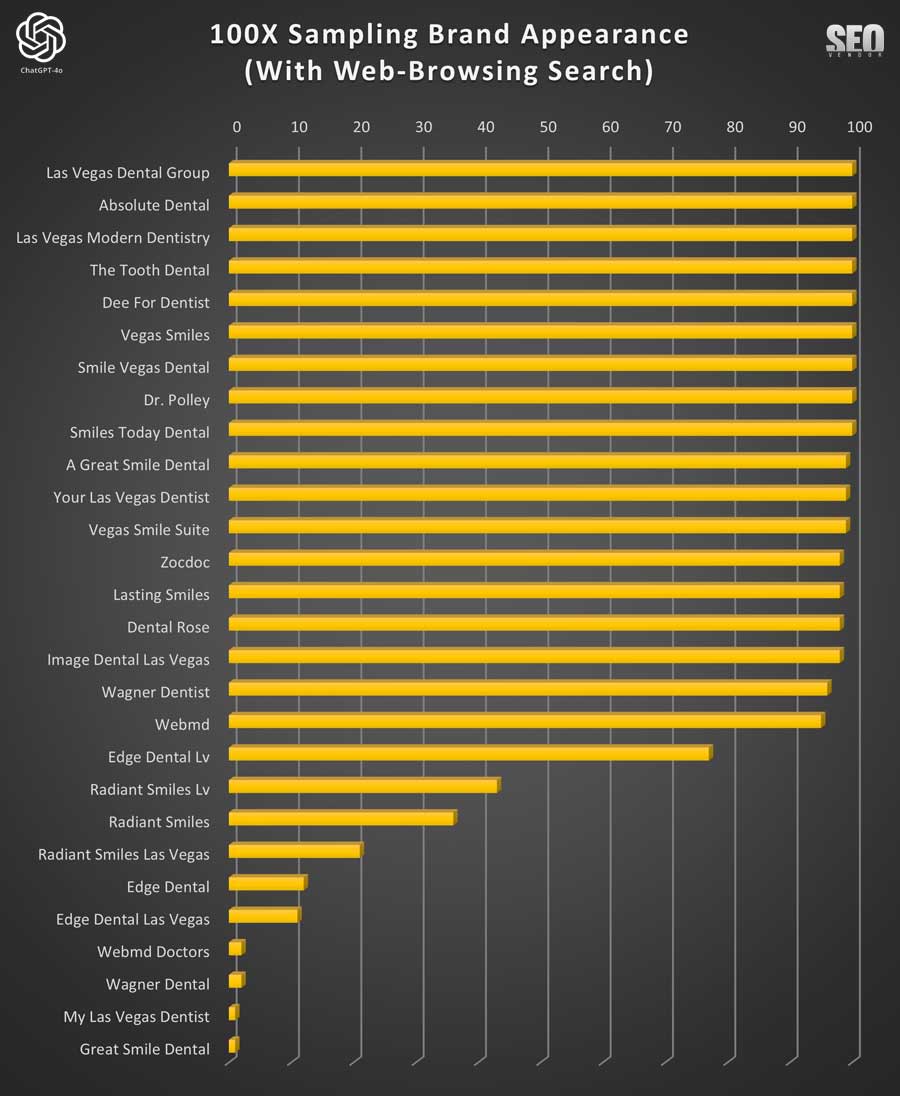
We have determined sites that appear less frequently, especially those that drop off by a significant among, are more likely to be replaced with other choices. Hence, we can see that there’s a sharp drop-off in appearance of brands that appear only occasionally.
100X ChatGPT With Web-Browsing Read-In
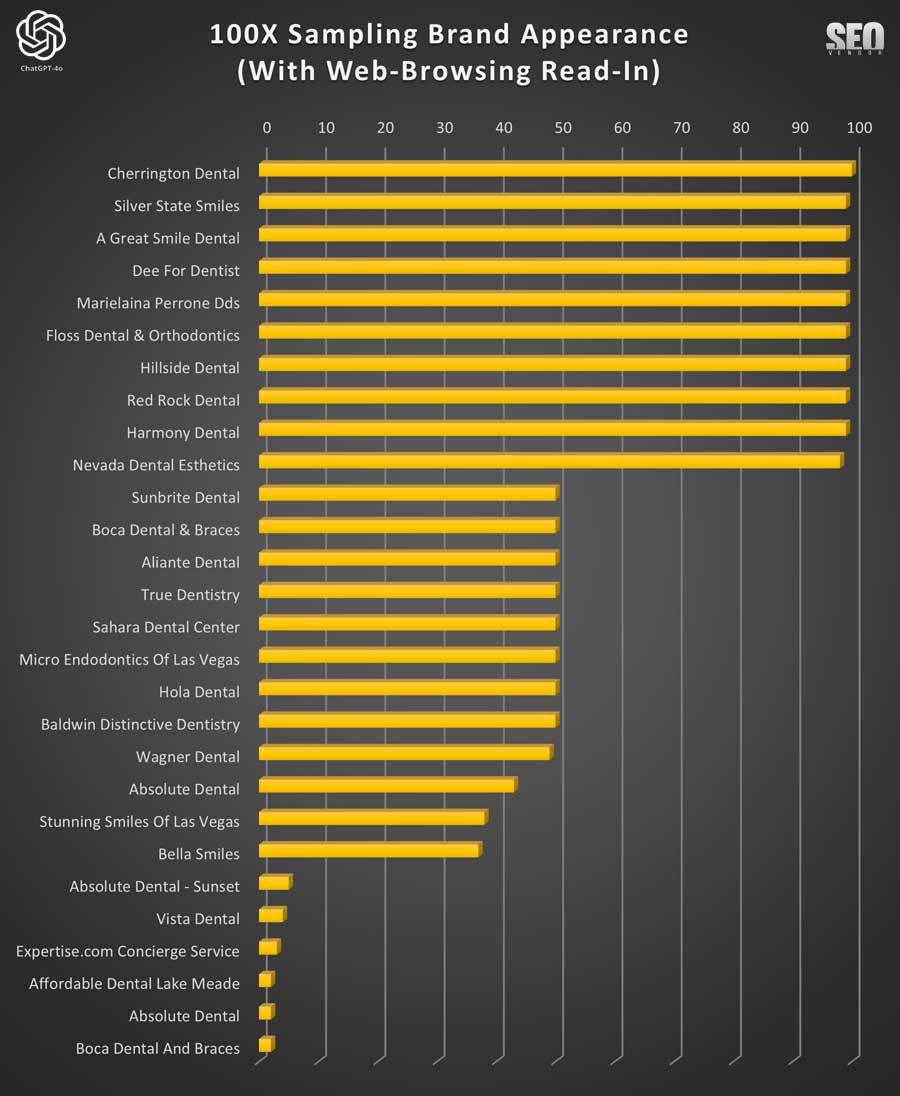
Brand Appearance for 100 Samples With Web-Browsing Read-In (Chart 23) illustrates how GPT-4o’s recommendations improved in specificity and accuracy when given the ability to read in articles. It shows the range of dentists that were recommended and how reading directly affected business selection.
An important observation is how significantly results change when the source content changes. What do we mean by this? We were able to test conditions that can occur over extended periods when web browsing returns different sets of sources.
Source material can change for a number of reasons:
- Changes in competition. For example, Stunning Smiles may have been ranked high in Bing but is now facing increased competition from similar dental practices.
- Changes in search algorithms, which affect the results returned by the search engine.
- Updates to the source material itself. For example, if Stunning Smiles was removed from the list of recommended dentists.
- Changes to the business itself. For example, the business closed, merged, or changed its service offerings, which affects its appearance in search results.
We observed dramatic changes in rankings from results returned by ChatGPT when this occurs. Because ChatGPT with web-browsing relies on source data, changes to the sources themselves can have an irreversible impact on some brands for the duration of the sampling test.
Besides discovering how brands can appear or disappear, the Brand Appearance for 100 Samples With Web-Browsing Read-In (Chart 24) shows a detailed analysis of niche provider mentions when read-in was enabled, indicating increased access to well-reviewed but lesser-known providers.
We witnessed differences between high and low rankings were minimal if we removed non-appearances (meaning removing samples where rank was non-existent). This demonstrates that as long as the source remains the same, rankings are stable. But if the tested source changes, then we can expect drastic fluctuation in rankings.
Overall, we can see from Chart 25 that businesses that remained even after source changes, held onto their appearance counts, while those that no longer appeared, had their appearance count cut drastically.
100X ChatGPT Web-Browsing Read-In + Prompt Variation
Chart 26 shows Brand Appearance for 100 Samples With Web-Browsing Read-In + Prompt Variation: This chart highlights how prompt variations affected brand recommendations across 100 samples.
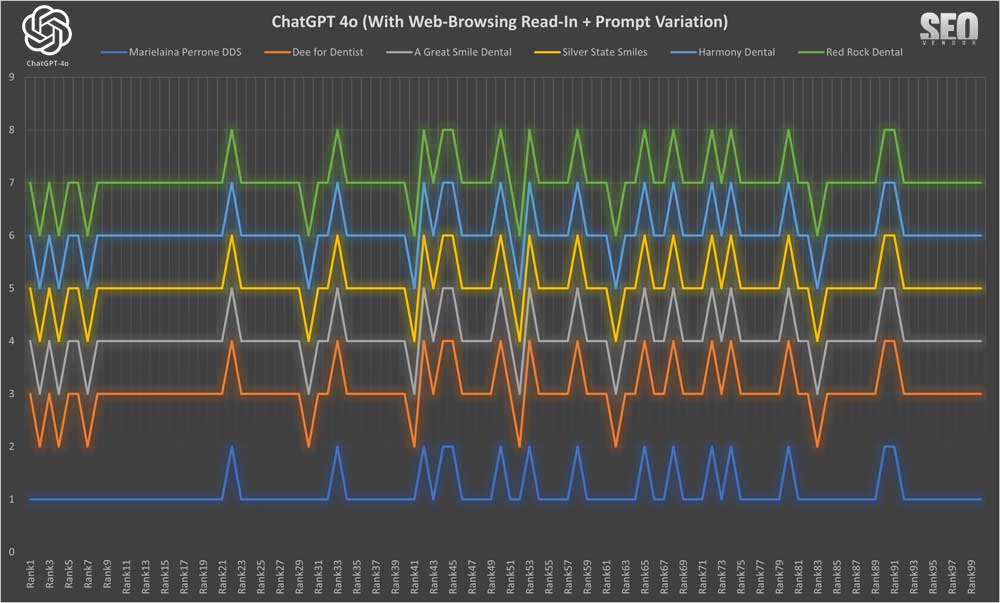
We observed with source material, adding prompt variation did not change the results by much. Rankings remained relatively consistent. You may notice that some samples shifted all rankings down by 1, with the #1 ranked practice missing. That is because in some samples, an invalid result would get returned from the sample, which would be thrown out.
Brand Appearance for 100 Samples With Web-Browsing Read-In + Prompt Variation (Chart 27) takes a deeper look into how slight prompt phrasing changes influenced the output and led to small variations in recommendations.
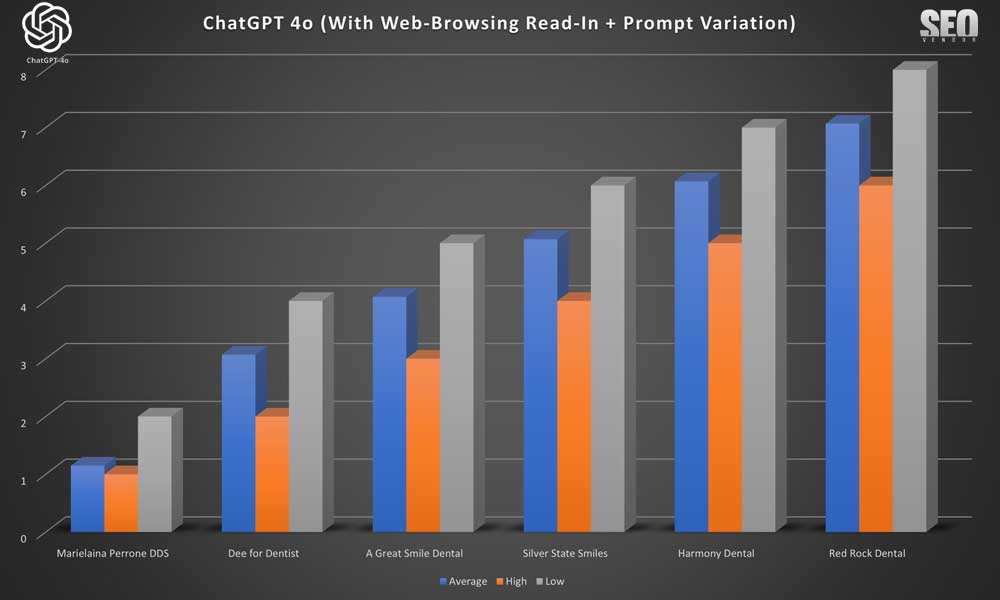
It’s possible because prompt variation was small, it did not impact the resulting variation between high and low rankings.
In Chart 28: Brand Appearance for 100 Samples With Web-Browsing Read-In + Prompt Variation, we take a deeper look into how slight prompt phrasing has minimal impact or influenced on the appearance of a brand.

Similar to 50x sampling, Chart 28 demonstrates that reading into review and recommendations only solidified the appearance of each business.
Key Findings for 100 Samples
- ChatGPT-4o Without Web-Browsing:
- In the absence of web-browsing capabilities, GPT-4o’s responses relied solely on its pre-existing knowledge.
- As expected, the recommendations were less up-to-date and often lacked specificity. In many cases, the responses included dentists that were well-known but not necessarily the most recent or best rated. There was also a notable degree of randomness in the recommendations when the model was prompted multiple times.
- ChatGPT-4o with Web-Browsing Search:
- When given access to web-browsing, GPT-4o provided significantly improved responses.
- The model was able to pull in more current information, which led to recommendations that included newer and more highly rated dentists. Interestingly, the quality of responses improved across all multi-sample prompts, indicating the benefit of browsing in accessing fresh data, but also meant less variation in responses.
- ChatGPT-4o with Web-Browsing Read-In:
- In this condition, GPT-4o not only conducted a search but also read specific web pages related to the query.
- The added read-in capability allowed the model to present more contextually accurate recommendations, often referring directly to specific ranking articles or reviews.
- The consistency across samples was also significantly higher compared to the no-browsing condition, that is, unless the underlying source changes.
- ChatGPT-4o with Web-Browsing Read-In + Prompt Variation:
- Minor changes in phrasing did not influenced the types of responses.
- The read-in capability helped maintain consistency in providing up-to-date and well-rounded responses.
- The variations in prompt phrasing tested the robustness of GPT-4o’s browsing and comprehension capabilities, showing that while the phrasing of a prompt can lead to subtle differences, the model generally maintained a consistent standard of recommendations as long a the source material remained the same.
Results from 10X Iteration Sampling
We saved one of our first tests for last. We crunched the numbers through each GPT-4o test 10 times. After reviewing all the data from competing 50X and 100X tests, we realized that 10X sampling still held an important role in understanding how variation in GPT results would look when we sampled at low rates.
Why Check 10 Iterations?
A low number of iterations might seem insufficient for reliable sampling, but in the real world, users are unlikely to run a prompt 50 or 100 times to determine a brand’s true appearance. A low number of samples might also provide enough insight; thus, we tested all sample cases at 10X.
10X ChatGPT Without Web-Browsing
To track 10X sampling relative to the same brands that were tracked at 50X and 100X, we graphed six brands that appeared frequently during those other tests to determine their visibility at 10X sampling.
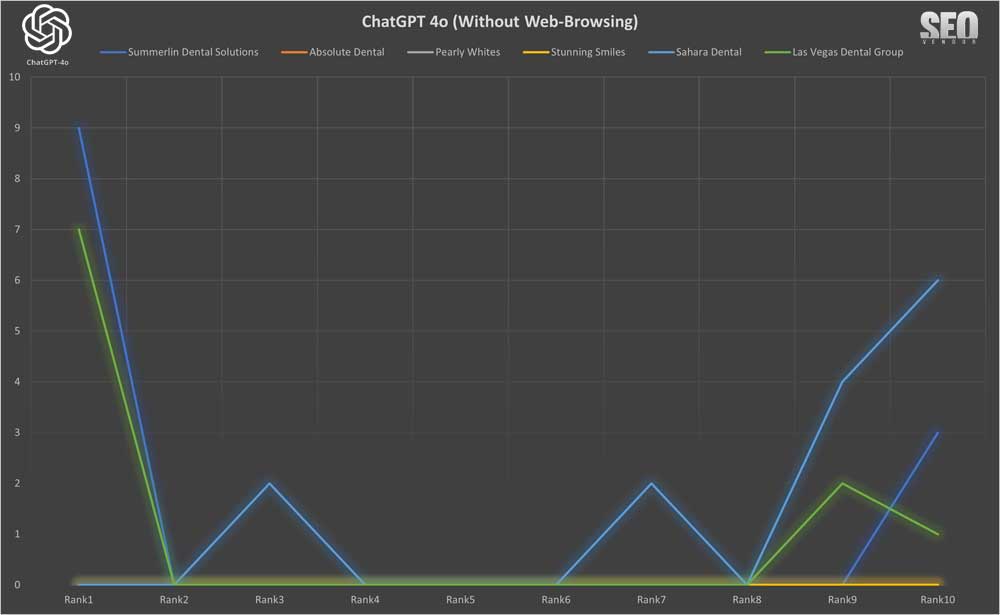
Chart 29 shows the Brand Appearance for 10 Samples Without Web-Browsing. This chart displays the brand recommendations across 10 samples without browsing capabilities. It highlights a lack of diversity, with popular businesses repeated frequently. In addition, you will notice that several businesses that were regular occurrences—Absolute Dental, Pearly Whites, and Stunning Smiles—did not appear at all.
In Brand Appearance for 10 Samples Without Web-Browsing (Chart 30), we see additional details about the consistency of certain well-known brands across 10 samples, showcasing the limitations of not having browsing access but also the same high variance in rankings.
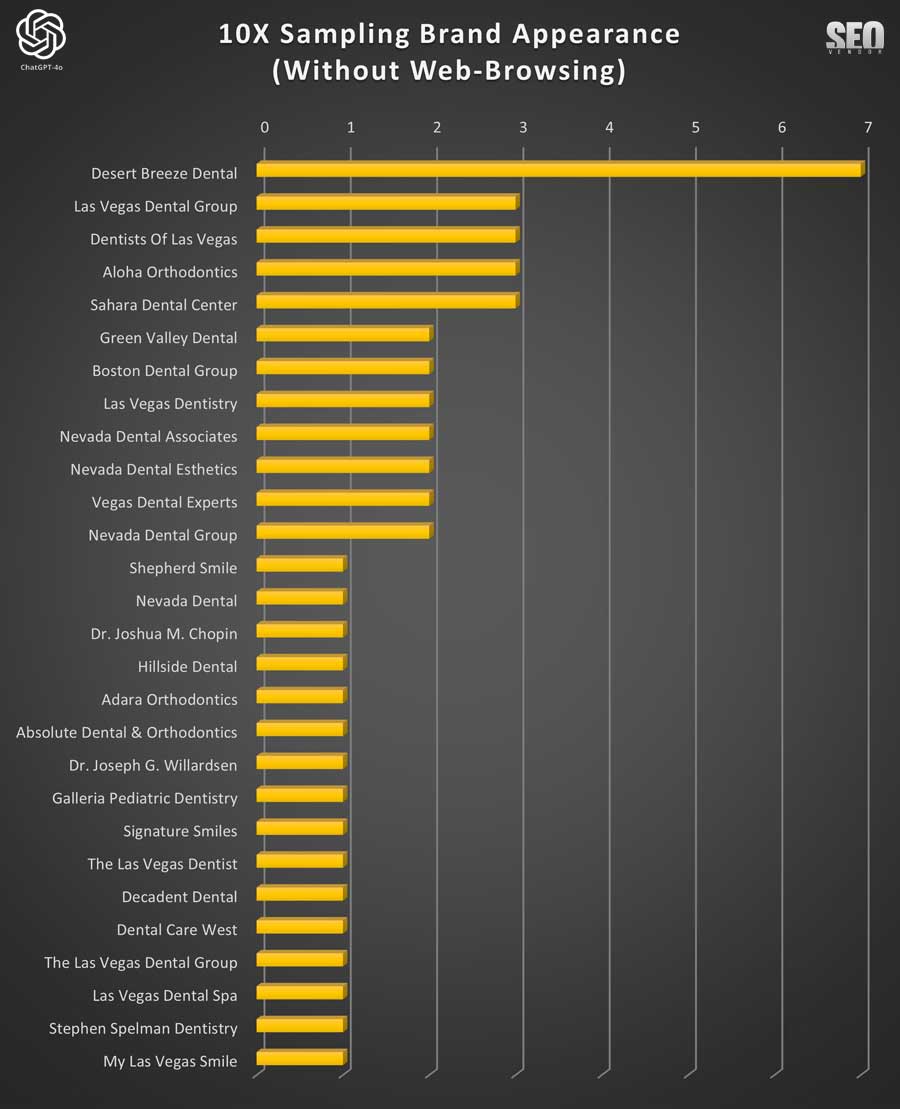
In the accumulated counts from 10 Samples Without Web-Browsing (Chart 31), we can see that there can be a heavy bias toward one brand, with an exponential decrease in the appearance of other brands.
10X ChatGPT With Web-Browsing Search
Results at 10X sampling with web browsing were even more predictable, as we did not witness any changes.
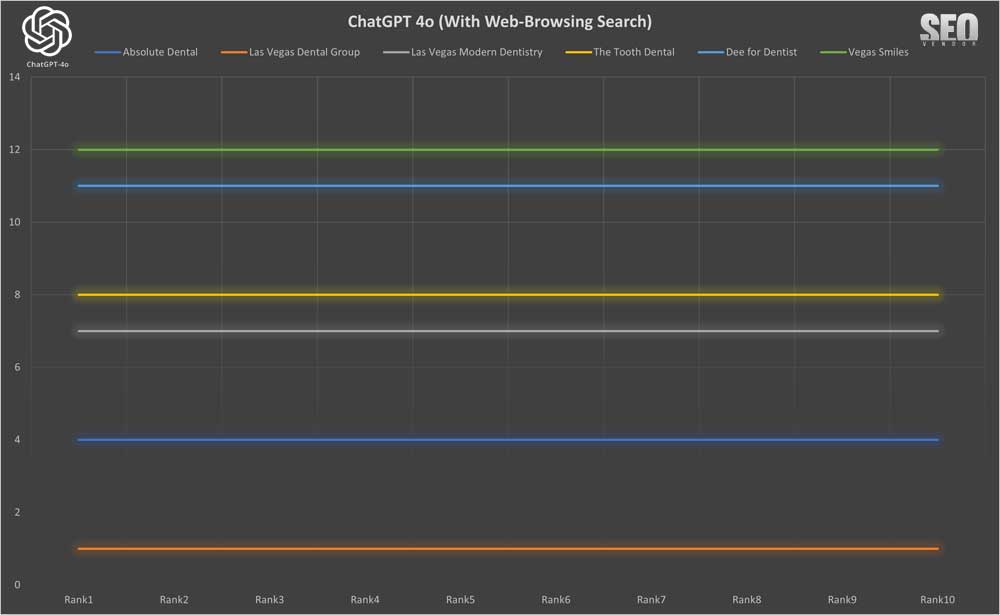
Since the sampling rate was low, Brand Appearance for 10 Samples With Web-Browsing Search (Chart 32) demonstrates how adding web-browsing search capabilities “locks in” businesses recommended by GPT-4o.
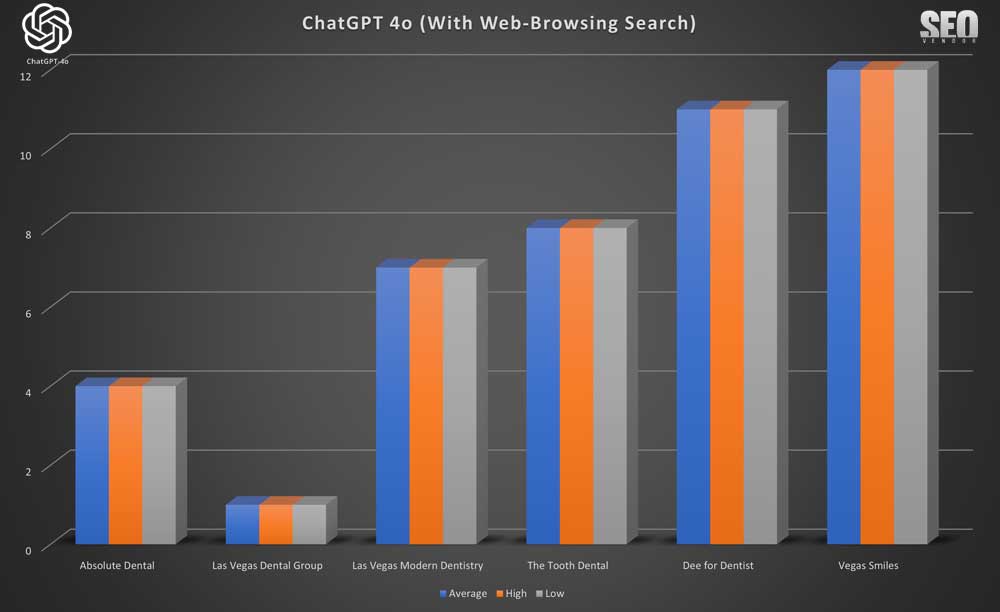
Brand Appearance for 10 Samples With Web-Browsing Search (Chart 33) highlights that no newer and diverse dentist offices emerged in the results due to the use of real-time web browsing; essentially, there was no change at all.
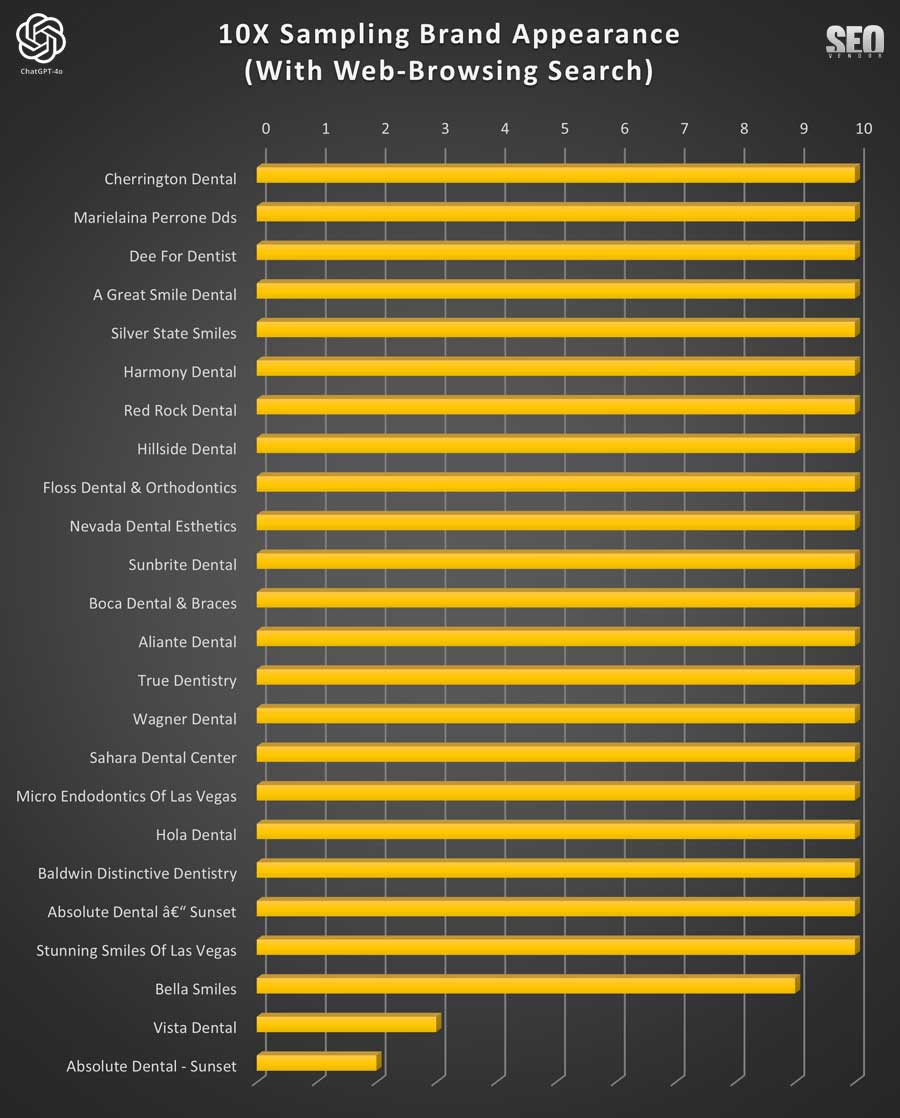
Chart 34 demonstrates that, at a low sampling rate and with the exception of a few practitioners, ChatGPT mostly returned consistent results.
10X ChatGPT With Web-Browsing Read-In
When we introduced reading into the content, ChatGPT behaved with similar consistency to having web-browsing capabilities but with slightly greater variance in appearance.
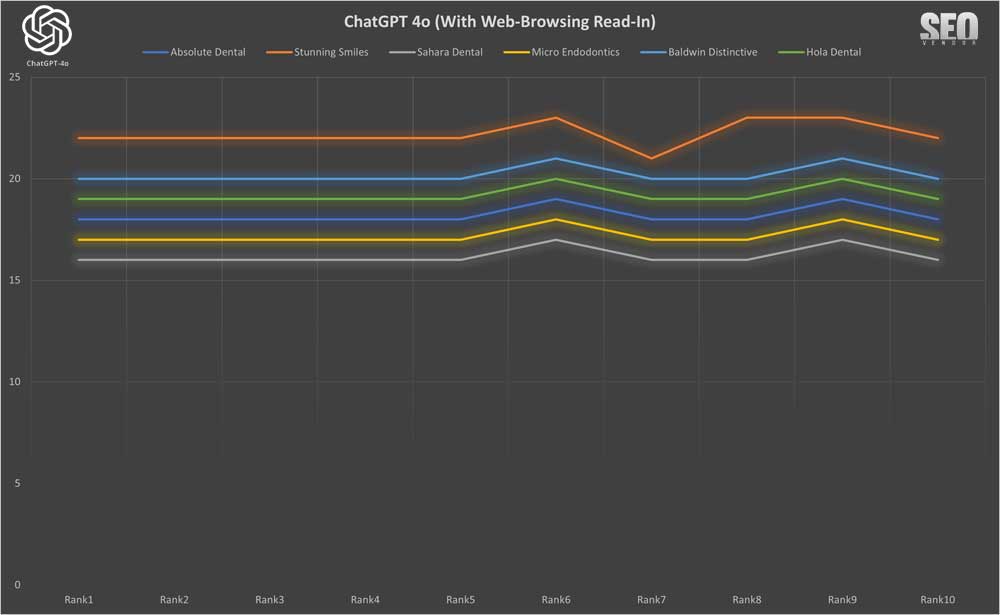
Brand Appearance for 10 Samples With Web-Browsing Read-In (Chart 35) shows the influence of web-browsing read-in on GPT-4o’s recommendations. While it does not necessarily increase the number of niche providers in the results, it changed their rank positions to a small degree.
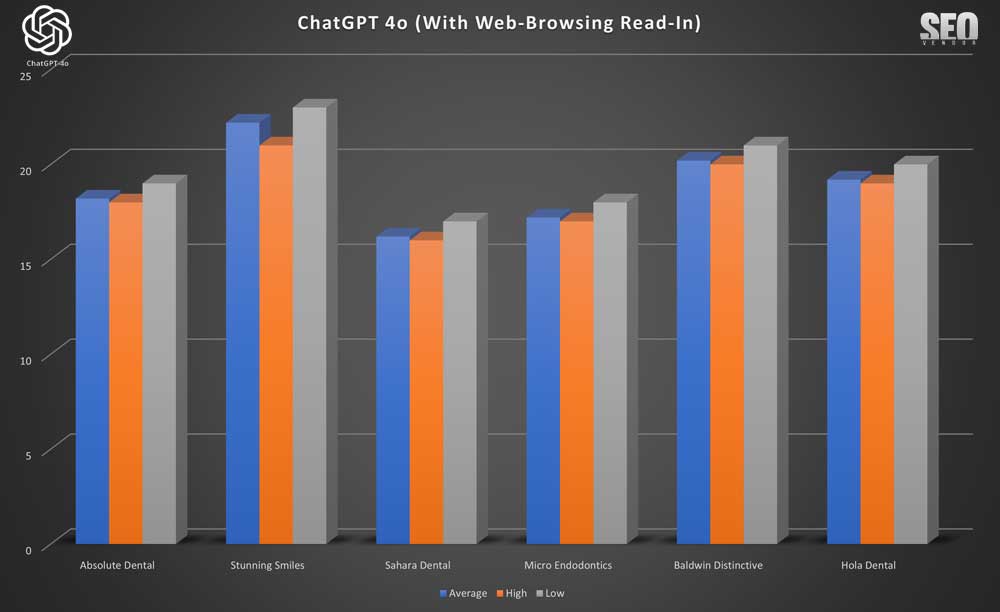
We can see that due to small changes in rankings, the max and min rankings in Brand Appearance for 10 Samples With Web-Browsing Read-In (Chart 36) did not vary much.
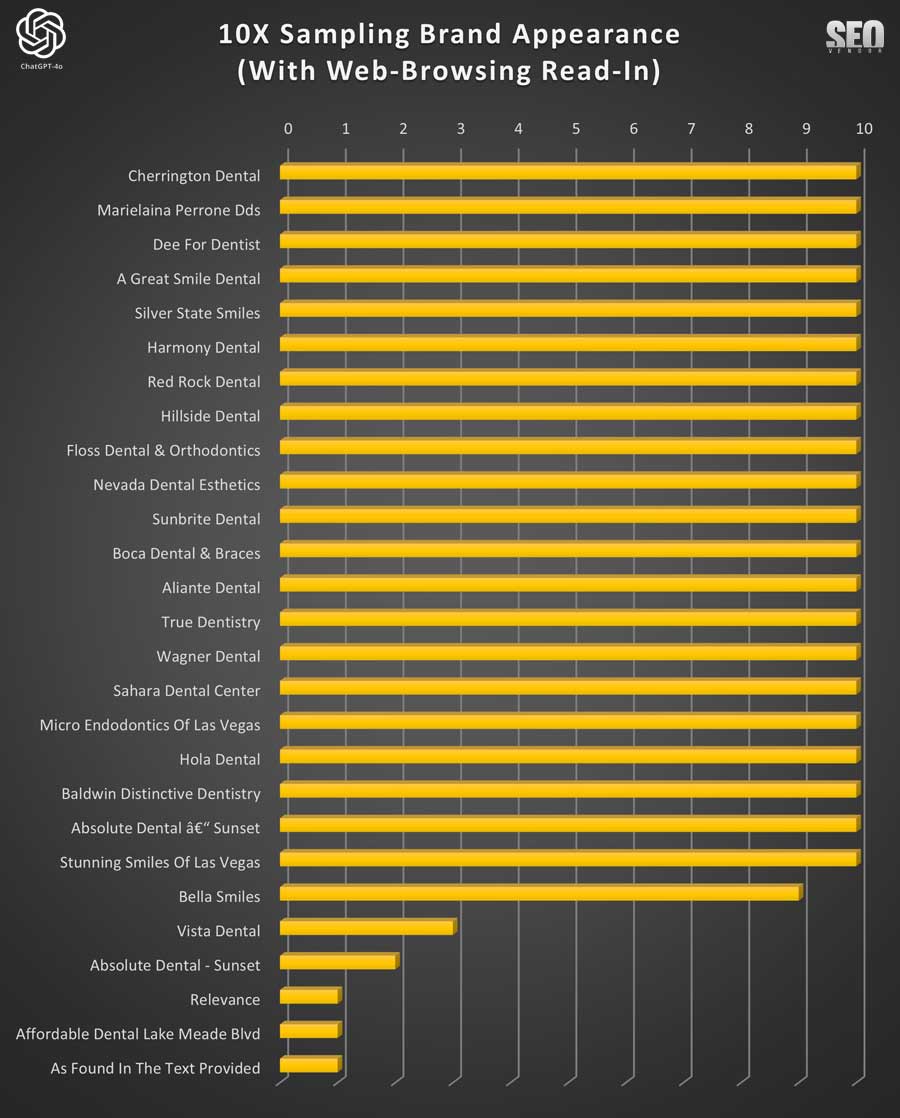
Overall, read-in web browsing did not change much behavior-wise from standard web browsing; however, you will notice that even at 10X sampling, the top result changed. This shows that reading in recommendations from the content sources still had an impact on which dentists appeared.
10X ChatGPT With Web-Browsing Read-In + Prompt Variation
We also tested 10X sampling with prompt variations to understand how low sampling rates impacted brand appearance.
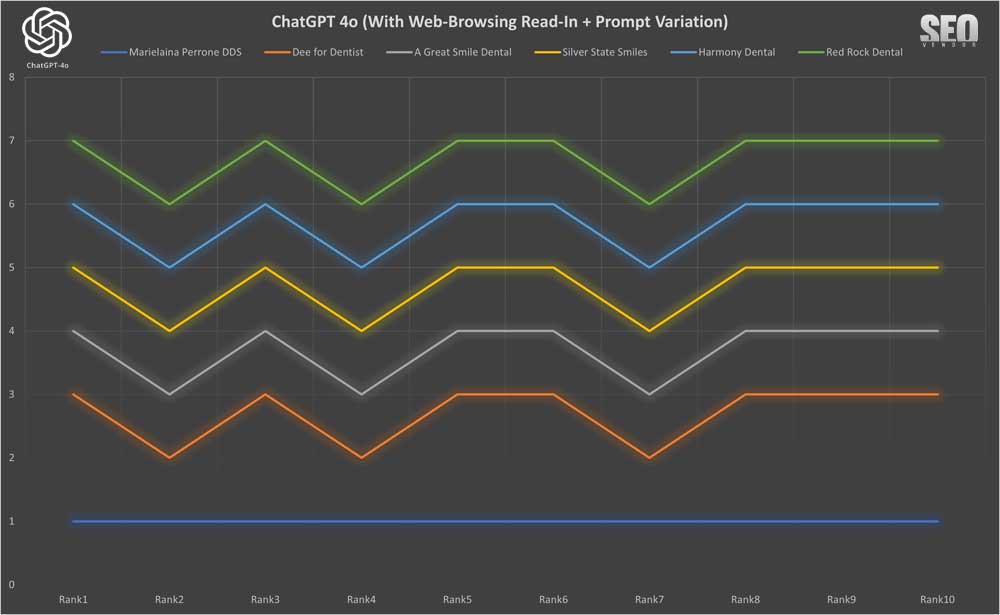
In Chart 38, Brand Appearance for 10 Samples With Web-Browsing Read-In + Prompt Variation, we see how using prompt variations influenced GPT-4o’s outputs by minimal amounts.
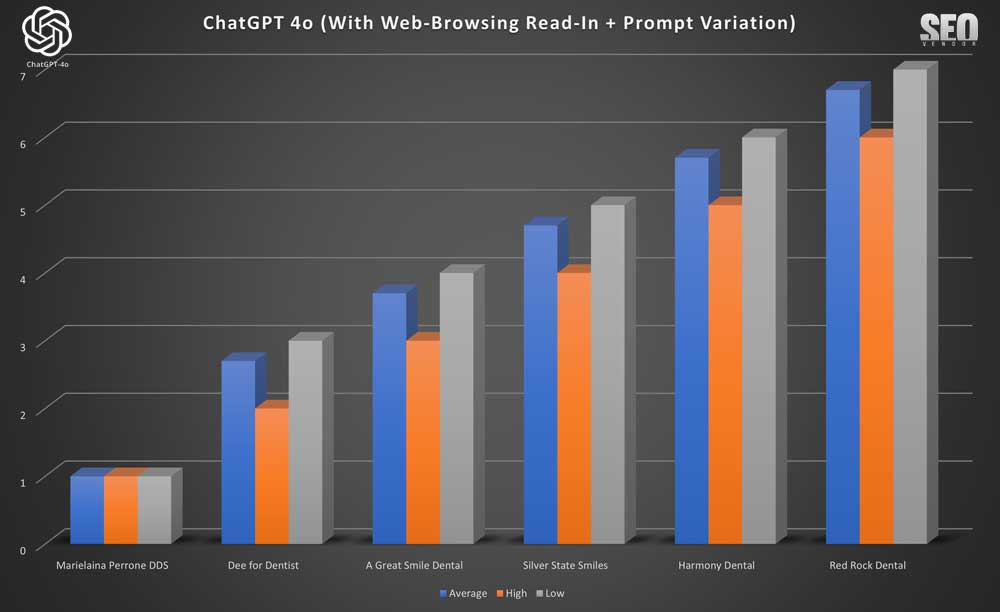
When we checked the Brand Appearance for 10 Samples With Web-Browsing Read-In + Prompt Variation (Chart 39), we saw a detailed analysis of the effect of prompt phrasing on output, showing a lower number of unique and diverse dentist offices recommended compared to 50X or 100X.
We can observe from Chart 40 that, when sampling at a low rate for Brand vs. Appearance, there is no change among the appearance of each of the brands. What this means is that, at a low sample rate, variations in the prompt have little to no impact. It’s not a matter of how the prompt is written as much as it is about the meaning of the prompt.
As long as the meaning is the same, the results will likely be the same as well.
Key Findings for 10 Samples
- Real-World Relevance of Low Iteration Sampling:
- Testing with 10 iterations mirrors typical user behavior, as most users are unlikely to run prompts 50 or 100 times.
- Low sample sizes can still provide valuable insights into the variation and reliability of ChatGPT’s responses.
- 10X ChatGPT Without Web-Browsing:
- Limited Diversity in Recommendations:
- Popular businesses were repeated frequently, showing a lack of diversity.
- Some brands that appeared in higher iteration tests (Absolute Dental, Pearly Whites, Stunning Smiles) did not appear at all.
- Bias Toward Certain Brands:
- A heavy bias toward one brand was observed, with a sharp decrease in the appearance of other brands.
- High Variance in Rankings:
- Rankings of recommended businesses showed significant variability across iterations.
- Limited Diversity in Recommendations:
- 10X ChatGPT With Web-Browsing Search:
- Consistency in Results:
- Adding web-browsing capabilities “locked in” the recommended businesses, resulting in highly consistent outputs.
- No new or diverse dentist offices emerged; the results remained the same across all iterations.
- Predictability:
- The use of real-time web browsing did not introduce changes at this sampling rate.
- Consistency in Results:
- 10X ChatGPT With Web-Browsing Read-In:
- Slight Increase in Variance:
- Introducing read-in capabilities led to minor changes in the rank positions of some providers.
- The top recommended dentist changed, indicating that reading content sources had some impact.
- Overall Consistency Maintained:
- Despite slight variations, the overall behavior remained similar to standard web browsing.
- Slight Increase in Variance:
- 10X ChatGPT With Web-Browsing Read-In + Prompt Variation:
- Minimal Impact of Prompt Variations:
- Variations in prompt phrasing had little to no effect on the results at low sampling rates.
- The meaning of the prompt influenced the outputs more than the specific wording used.
- Consistency in Brand Appearances:
- No significant change was observed in the appearance of brands compared to other 10X tests.
- Minimal Impact of Prompt Variations:
- General Observations:
- Impact of Sampling Rate:
- Low sampling rates result in high consistency and limited diversity in recommendations.
- Significant changes in brand appearances are more likely to be observed with higher iteration sampling.
- Importance of Prompt Meaning:
- The underlying intent of the prompt is crucial; as long as the meaning remains the same, the results are likely to be consistent.
- Effect of Browsing Capabilities:
- Web-browsing and read-in features enhance consistency but do not necessarily increase diversity at low sampling rates.
- Impact of Sampling Rate:
Final Test Conclusion
This in-depth study demonstrates the variability and adaptability of GPT-4o in generating business recommendations under different prompting conditions. The addition of browsing and read-in capabilities markedly improved the relevance and quality of the recommendations provided. However, the study also highlights the sensitivity (or lack thereof) of LLMs to prompt phrasing, suggesting that the way a user frames a query does not always influence the outcome.
From a marketing perspective, here’s what we’ve learned:
- Branding is going to be a significant signal to have a presence in LLMs.
- LLMs like ChatGPT are trained with a wealth of small business brand and website knowledge.
- Business knowledge in ChatGPT is nowhere near perfect. It can hallucinate names or create incorrect variations of names.
- Website knowledge is even worse than branding knowledge in ChatGPT.
- Chatbots are increasingly important to businesses. More tests like these are needed.
As LLMs continue to evolve, understanding the impact of prompt phrasing, browsing capabilities, and RAG data retrieval on their performance will be crucial for optimizing their use in real-world business applications, such as GAIO (Generative AI Optimization).
We hope the insights gained from this study will offer valuable guidance for businesses and developers looking to harness LLMs for creating or optimizing LLM rankings/recommendation systems and similar use cases.
If you would like to see us run a specific test case or make further studies, contact us here.



")
